로컬 LLM을 한 번 띄워본 사람이라면 처리량 얘기에서 반드시 vLLM을 만난다. “HuggingFace보다 최대 24배 빠르다”는 문장은 거의 상투구가 됐는데, 정작 “왜 빠른가”를 한 줄로 답해보라면 막힌다. 나도 그랬다. 그래서 PagedAttention 논문을 펴고 그 핵심을 운영체제(OS) 비유로 다시 풀어봤다. 결론부터 말하면 vLLM의 빠름은 마법이 아니라 50년 묵은 OS 교과서의 아이디어를 KV 캐시에 옮겨온 것이다. 이 글은 그 원리를 직관으로 이해하는 데 집중한다.

그림 1. vLLM 공식 문서 첫 화면
TL;DR
- vLLM은 UC 버클리 연구진(Kwon et al.)이 SOSP 2023에서 발표한 PagedAttention 논문에서 출발한 오픈소스 LLM 서빙 엔진이다.
- PagedAttention은 OS의 가상 메모리·페이징을 KV 캐시에 적용해, 기존 시스템이 버리던 메모리 60~80% 낭비를 4% 미만으로 줄인다.
- 그렇게 확보한 여유로 동시 batch를 키우고, continuous batching으로 빈 슬롯을 즉시 채워 HuggingFace Transformers(순정) 대비 최대 24배 처리량을 낸다. (이미 최적화된 SOTA 서빙 시스템 대비로는 2~4배.)
- 단, 이 이점은 동시 요청이 많은 GPU 서버에서 나온다. vLLM과 Ollama는 “어느 게 더 빠른가”가 아니라 목적이 다르다.
vLLM이란? 왜 다들 vLLM을 말하나
vLLM은 UC 버클리 연구진(Woosuk Kwon 외)이 SOSP 2023에서 발표한 PagedAttention 논문(arXiv:2309.06180)에서 출발한 오픈소스 LLM 서빙 엔진이다. 이름의 v는 virtual(가상)에서 왔고, 이게 글 전체의 힌트다.
Ollama로 로컬 LLM을 띄워본 단계가 “일단 돌려보는” 것이었다면, vLLM은 “처리량을 짜내는” 엔진이다. 지금은 사실상 표준 서빙 엔진으로 통하고, 그 빠름의 핵심이 PagedAttention과 continuous batching 두 가지다. 이 글은 이 둘을 OS 비유로 이해하는 게 목표다. “그럼 내 맥에서 실제로 돌아가나”는 별도 글에서 다룬다(아래 링크).
KV 캐시와 단편화 — 왜 기존 방식이 메모리를 60~80% 버렸나
PagedAttention을 이해하려면 먼저 KV 캐시가 뭔지, 그리고 기존 방식이 왜 메모리를 그렇게 많이 버렸는지부터 봐야 한다.
LLM은 토큰을 하나씩 생성하면서 앞서 본 토큰들의 key/value 벡터를 재사용한다. 매번 다시 계산하면 느리니 한 번 계산한 key/value를 메모리에 저장해두는데, 이게 **KV 캐시(KV cache)**다. 시퀀스가 길어질수록 저장할 양이 늘어 KV 캐시는 시퀀스 길이에 따라 선형으로 커진다.
문제는 기존 시스템이 이 캐시를 요청마다 하나의 연속(contiguous)된 메모리 블록으로 잡으려 했다는 점이다. 그 과정에서 두 종류의 낭비가 생겼다.
- 내부 단편화(internal fragmentation): 요청이 들어오면 최대 시퀀스 길이(max_seq_len)만큼 공간을 미리 예약(over-reservation)하는데, 실제 생성 길이는 대부분 그보다 짧아 예약 공간 상당수가 비어서 버려진다.
- 외부 단편화(external fragmentation): 요청마다 길이가 제각각이라 연속 공간을 잡으려다 보면 메모리 사이사이에 못 쓰는 틈이 생긴다.
이 둘이 합쳐져 얼마나 버려졌느냐. vLLM 공식 블로그는 “existing systems waste 60% – 80% of memory due to fragmentation and over-reservation”이라고 못 박는다. 절반을 훌쩍 넘는 GPU 메모리가 실제 데이터가 아니라 단편화와 과잉 예약으로 사라지고 있었다는 뜻이다. 메모리가 모자라면 동시에 처리할 수 있는 요청 수가 줄고, 그게 곧 처리량 한계가 된다. 여기까지가 “왜 기존 방식이 느렸나”의 답이다.
PagedAttention 직관 — OS 페이징을 KV 캐시에 적용하면
여기가 이 글의 핵심이다. PagedAttention이 어떻게 그 60~80% 낭비를 4% 미만으로 줄이는지, 운영체제 비유로 풀어본다.
논문 저자들이 직접 밝힌 출발점은 이렇다. vLLM 블로그는 PagedAttention을 “an attention algorithm inspired by the classic idea of virtual memory and paging in operating systems”라고 소개한다. 50년 가까이 된 OS의 가상 메모리 아이디어를 KV 캐시에 그대로 가져온 것이다.
운영체제는 프로그램에게 “연속된 큰 메모리”라는 환상을 준다. 하지만 실제 물리 메모리는 **페이지(page)**라는 고정 크기 조각으로 쪼개져 여기저기 흩어져 있고, **페이지 테이블(page table)**이 “이 프로그램의 3번째 페이지는 물리 메모리 어디”라고 매핑해준다. 프로그램은 연속이라 믿지만 물리적으론 흩어져 있는 것이다. PagedAttention은 이 구조를 그대로 KV 캐시에 적용한다.
- 고정 크기 KV block = OS의 페이지. KV 캐시를 하나의 연속 공간이 아니라 고정 크기 block 단위로 쪼갠다.
- logical → physical 매핑 테이블 = OS의 페이지 테이블. 각 시퀀스는 logical block table을 통해 GPU 메모리에 흩어진 비연속(non-contiguous) physical block을 가리킨다.
이렇게 하면 연속 공간을 미리 크게 잡을 필요가 사라진다. 시퀀스가 자라면 그때그때 빈 physical block 하나를 새로 할당하면 그만이다. 외부 단편화는 block이 어디 있든 매핑으로 이어 붙이니 사라지고, 내부 단편화는 시퀀스의 마지막 block에서만 발생한다. 마지막 block에 채 안 찬 자투리만 남기 때문이다.
그 결과가 vLLM 블로그의 표현으로 “memory waste only happens in the last block of a sequence … a mere waste of under 4%“다. 60~80%에서 4% 미만으로. OS가 프로그램에게 연속 메모리라는 환상을 주면서 실제로는 페이지 단위로 흩어 담듯, PagedAttention은 KV 캐시를 block 단위로 흩어 담고 매핑 테이블로 이어 붙인다. 비유라기보다 거의 그대로 옮겨온 설계다.
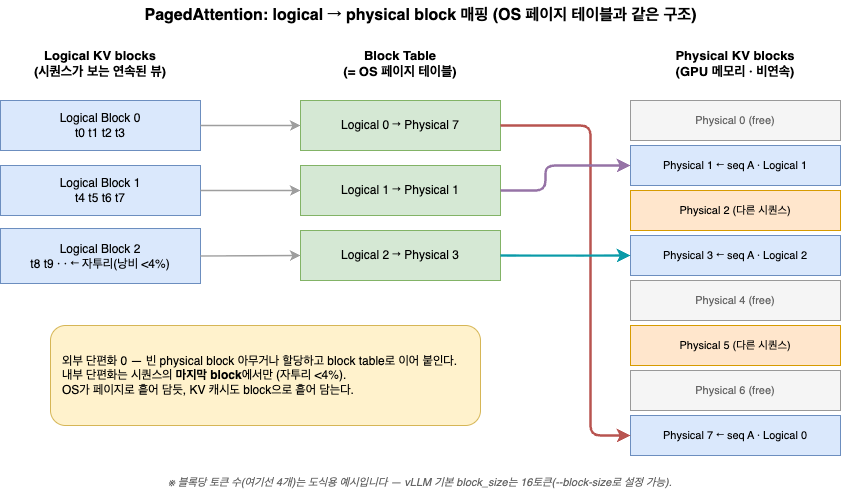
그림 2. PagedAttention의 logical-physical block 매핑 — OS 페이지 테이블과 같은 구조
여담이지만 OS의 fork()도 그대로 들어와 있다. 같은 프롬프트에서 여러 응답을 뽑을 때(parallel sampling·beam search) 프롬프트 KV block을 여러 출력이 공유하다가 갈라지는 시점에만 복사한다(Copy-on-Write). 덕분에 메모리를 최대 55% 더 아낀다.
continuous batching — 빈 슬롯을 즉시 채우는 시간의 최적화
PagedAttention이 메모리를 아껴 batch를 키울 여유를 만들었다면, 그 여유를 꽉 채우는 건 continuous batching이다. vLLM의 빠름은 이 둘이 한 쌍이라는 데서 나온다.
기존의 **static batching(정적 배치)**은 배치에 묶인 요청들이 전부 끝날 때까지 다음 배치를 시작하지 못한다. 한 요청은 500토큰을 생성하는데 다른 요청은 20토큰만 만들고 끝났다면, 짧은 요청이 점유하던 자리는 긴 요청이 끝날 때까지 빈 채로 논다(idle).
**continuous batching(연속 배치 처리)**은 이걸 바꾼다. iteration-level scheduling이라고도 부르는데, 매 토큰 생성 iteration마다 배치 구성을 다시 짠다. 한 시퀀스가 끝나면 그 빈 슬롯에 대기 중이던 새 요청을 즉시 끼워 넣는다. 원전은 Orca(Yu et al., OSDI 2022)이고, Anyscale의 설명이 이 과정을 그림으로 잘 풀어준다. GPU가 놀 틈을 주지 않는 스케줄링인 셈이다.
한 문장으로 정리하면, PagedAttention이 공간(메모리) 차원의 최적화라면, continuous batching은 시간(스케줄링) 차원의 최적화다. 인과 사슬은 이렇게 이어진다 — PagedAttention이 단편화 낭비를 줄여 동시 batch를 키울 메모리를 만들고 → continuous batching이 빈 슬롯을 즉시 채운다 → 처리량이 폭증한다. 그 폭증의 크기가 그 유명한 “24배”다. 다만 여기서 한 가지는 반드시 짚고 가야 한다.
“24배 vs 2~4배” — 비교 대상을 섞으면 안 된다
수치 무엇 대비 무엇 조건 · 출처 최대 24배 vLLM vs HuggingFace Transformers(순정 파이프라인) LLaMA-7B on A10G, 13B on A100 (vLLM 블로그) 최대 3.5배 vLLM vs TGI 동일 환경 (vLLM 블로그) 2~4배 vLLM vs SOTA(FasterTransformer, Orca) 동일 latency 유지 시 (논문) 60~80% → <4% 기존 시스템 vs PagedAttention (메모리 낭비) vLLM 블로그 “vLLM은 24배 빠르다”를 비교 대상 없이 인용한 글이 많은데, 24배는 아무 최적화도 안 한 HuggingFace Transformers 대비다. 이미 최적화된 서빙 시스템(FasterTransformer, Orca) 대비로는 2~4배. 같은 논문의 두 숫자가 다른 건 모순이 아니라 비교 상대가 다르기 때문이다.
vLLM vs Ollama — 처리량이 아니라 목적이 다르다
원리를 알고 나면 자주 나오는 질문이 “그럼 Ollama랑 뭐가 다른가”다. Red Hat은 둘의 관계를 이렇게 정리한다. “Ollama is ideal for local development and prototyping, while vLLM is built for high-performance production deployments“. Ollama는 llama.cpp + Metal 기반으로 단일 사용자 prototyping에, vLLM은 PagedAttention 기반으로 동시 요청 처리량 서빙에 맞춰져 있다. 둘 다 OpenAI 호환 API라 엔드포인트만 바꾸면 같은 코드가 붙는다. 어느 게 “더 좋다”가 아니라 목적이 다르다. 이 차이가 실제 기기 위에서 어떻게 드러나는지는 아래 후속 글에서 수치로 확인한다.
자주 묻는 질문
Q1. vLLM이란 무엇인가요? UC 버클리 연구진(Kwon et al.)이 SOSP 2023에서 발표한 PagedAttention 논문에서 출발한 오픈소스 LLM 서빙 엔진으로, 지금은 사실상 표준으로 쓰인다.
Q2. PagedAttention은 왜 빠른가요? OS의 가상 메모리·페이징을 KV 캐시에 적용해 메모리 낭비를 60~80%에서 4% 미만으로 줄이고, 그 여유로 batch를 키워 처리량을 올린다.
Q3. KV 캐시란 무엇인가요? 이미 계산한 토큰의 key/value 벡터를 저장해두고 재사용하는 캐시다. 시퀀스 길이에 따라 메모리가 선형으로 늘어난다.
Q4. continuous batching이란 무엇인가요? 매 iteration마다 배치를 다시 짜서, 한 요청이 끝나는 즉시 빈 슬롯에 새 요청을 끼워 넣는 스케줄링이다. PagedAttention이 공간을 아꼈다면 이쪽은 시간을 아낀다.
Q5. vLLM은 정말 24배 빠른가요? 24배는 아무 최적화도 안 한 HuggingFace Transformers 순정 대비고, 이미 최적화된 서빙 시스템(FasterTransformer, Orca) 대비로는 2~4배다. 같은 논문의 수치이며 비교 상대가 다를 뿐이다.
Q6. vLLM과 Ollama의 차이는 무엇인가요? 목적이 다르다. Ollama는 단일 사용자 prototyping에, vLLM은 다중 동시 요청 처리량 서빙에 맞춰져 있다. 둘 다 OpenAI 호환 API라 엔드포인트만 바꾸면 같은 코드가 붙는다.
정리 — 빠름은 마법이 아니라 OS 교과서다
vLLM의 빠름은 두 축에서 나온다. PagedAttention이 OS 페이징으로 메모리 낭비를 60~80%에서 4% 미만으로 줄여 batch를 키울 공간을 만들고, continuous batching이 빈 슬롯을 즉시 채워 그 공간을 꽉 쓴다. 공간과 시간 두 차원의 최적화가 합쳐진 결과가 그 “24배”다. 새로운 마법이 아니라 50년 묵은 가상 메모리 아이디어를 KV 캐시에 옮겨온 것이다 — 그래서 한 번 그림으로 이해하면 잘 안 잊힌다.
원리를 알았으니 다음은 “내 손에서 도는가”다. 직접 돌려보고 싶다면 아래 관련 글의 M3 Pro 실측편으로 이어진다. CUDA GPU 처리량 벤치, sglang·vLLM·Ollama 엔진 결정 트리는 별도 글로 준비 중이다.
관련 글
- SGLang은 왜 빠른가 — RadixAttention과 prefix 공유의 직관 — 본 글의 원리 짝꿍. PagedAttention이 공간(메모리)을 아낀다면, RadixAttention은 상태(prefix 재계산)를 아낀다. 두 기법이 같이 쓰일 수 있는 이유와 2025~2026년 vLLM APC 흡수 시점 차까지.
- KV 캐시가 뭐길래 — 긴 컨텍스트가 빠르게 비싸지는 이유 — 본 글이 다룬 PagedAttention의 진앙. KV 캐시 자체가 왜 메모리·비용 폭증의 원인인지 책상 비유로 푼 학습 시리즈 뿌리 글. Llama 3.1 8B 컨텍스트별 KV 4GB~128GB + Claude 200K·Gemini 1M 가격 임계점까지.
- M3 Pro에서 vLLM 돌려보기 — Mac 3경로와 솔직한 한계 (2026) — 이 글에서 본 원리가 실제 맥북 위에서 도는지 확인하고 싶다면. Apple Silicon 설치 3경로(CPU backend·vllm-metal·Docker Model Runner)와 단일 스트림 vs 동시 4 요청 실측, 그리고 왜 혼자 쓰면 Ollama가 더 빠른지까지.
- Ollama로 M3 Pro 맥북에 로컬 LLM 띄우기 — 30분 실측 가이드 — vLLM 이전에 로컬 LLM을 가장 단순하게 띄워보는 길. 이 글의 “목적 차이” 맥락의 출발점이다.
- Claude API 비용 완벽 가이드 2026 — 토큰 단가·캐싱·배치 할인 — 로컬에서 직접 서빙하는 비용과 클라우드 API 비용을 비교하고 싶을 때 기준점.
참고 자료
- Efficient Memory Management for Large Language Model Serving with PagedAttention — arXiv:2309.06180 (SOSP 2023) — PagedAttention 원논문
- vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention — vLLM Blog (2023-06-20) — 60~80%→<4%, 24배·3.5배 수치 출처
- How continuous batching enables 23x throughput in LLM inference — Anyscale — continuous batching·Orca 설명
- Ollama or vLLM? How to choose the right LLM serving tool — Red Hat Developer (2025-07-08) — vLLM vs Ollama 목적 차이
- 최대 24배 빠른 vLLM의 비밀 — 스캐터랩 블로그 — 공간·시간 최적화 한국어 정리
OS 페이징 비유가 정말 도움이 되네요. KV 캐시 단편화 때문에 성능이 얼마나 향상되는지 궁금해졌어요.
도움이 되셨다니 다행이네요!