Gemini 2.5 Pro 가격표를 보면 한 줄에 눈이 멈춘다. 200K 토큰을 넘는 순간 input 단가가 정확히 두 배가 된다. Claude도 2024 시점엔 비슷한 임계점이 있었다. “왜 갑자기 두 배지?”라는 질문에 한국어 인터넷은 “1M 컨텍스트는 1000배 비싸진다” 같은 단정으로 답하곤 한다. 원전을 찾으려고 한참 헤맸는데 못 찾았다. 대신 공식 자료들을 따라가며 진짜로 일어나는 일을 풀어봤다 — 답은 책상 위에 펼쳐둔 책 더미에 있다. 이 글은 그 KV 캐시와 컨텍스트 윈도우(context window)의 무게를 한국어 직관으로 정리한다.
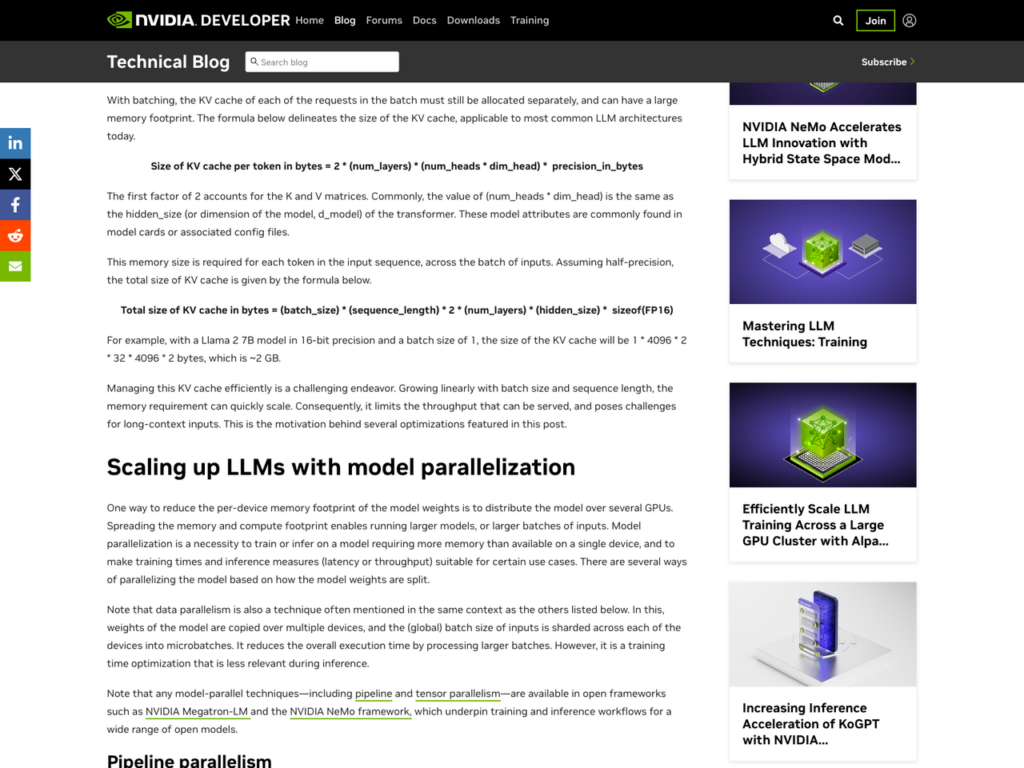
그림 1. NVIDIA 공식 블로그의 KV 캐시 공식 설명
TL;DR
- KV 캐시는 트랜스포머가 매 토큰의 key·value 벡터를 보관하는 메모리다. 컨텍스트 윈도우가 길어질수록 무게가 늘어 GPU 메모리도 빠르게 차고 API 비용도 같이 올라간다.
- Llama 3.1 8B(BF16) 기준 토큰 1개가 128 KB. 32K 컨텍스트 = 4 GB, 128K = 16 GB, 1M = 128 GB. 모델 가중치(16GB)는 별도다.
- Gemini 2.5 Pro는 200K 초과 시 input 2배·output 1.5배(Google AI 공식). Claude는 2024 시점엔 같은 임계점이었으나 2026 현재 Opus 4.8·4.7·4.6·Sonnet 4.6은 1M까지 standard pricing이다 — 뒤에서 시점 차로 따로 적었다.
- PagedAttention(공간)·RadixAttention(상태)·GQA(원천) 셋은 같은 KV 캐시 문제를 다른 축에서 푸는 한 묶음이다.
KV 캐시·Context Window가 뭔가
용어부터 간단히 정리한다. KV 캐시는 트랜스포머가 매 토큰의 key·value 벡터를 메모리에 저장해 다음 토큰을 만들 때 재사용하는 자료구조다. **컨텍스트 윈도우(context window)**는 한 번에 그 KV로 보관할 수 있는 토큰 수의 한도다. Anthropic 공식 문서는 컨텍스트 윈도우를 모델의 “working memory”라고 부른다.
이 글의 자리는 vLLM이 PagedAttention으로 단편화를 푼 이야기와 SGLang이 RadixAttention으로 prefix 재계산을 푼 이야기의 뿌리다. 두 글이 KV 캐시의 증상(단편화·중복 계산)을 푼 약이었다면, 여기서는 그 진앙인 KV 캐시 자체를 본다. Yao Fu(2024)는 긴 컨텍스트 배포의 어려움을 KV 캐시 단일 원인으로 환원한다.
책상 비유로 KV 캐시 풀어보기
LLM은 토큰을 하나씩 생성한다. 다음 토큰을 만들려면 어텐션이 앞 토큰들의 key·value 벡터를 전부 봐야 하고, 매번 다시 계산하기엔 비싸니 메모리에 저장해둔다 — 그게 KV 캐시다. 토큰을 1개 더 생성할 때마다 새 K·V 한 묶음이 메모리에 더해진다. 1개씩, 선형으로.
SGLang에서 RadixAttention을 도서관 책장으로 풀었듯, KV 캐시 자체는 책상 위에 펼친 책 더미 비유로 풀린다.
책상 한 장을 떠올려보자. 책상의 크기가 컨텍스트 윈도우 한도다 — 8K, 128K, 1M. 한 페이지는 토큰 1개고, 그 페이지에 그 토큰의 key·value 벡터가 적혀 있다. 펼쳐둔 책 전체의 무게가 KV 캐시 메모리다. 한 페이지의 무게는 모델 크기·정밀도·KV head 수에 따라 정해진다 — Llama 3.1 8B(BF16) 한 페이지가 128 KB인데, 정확 계산은 뒤에서 다시 본다.
다음 토큰을 쓰려면 책상 위 모든 페이지를 한 번씩 훑어야 한다. 그게 어텐션 연산이다. 책상에 펼친 책이 1만 페이지면 새 한 페이지를 더 쓸 때 1만 페이지를 같이 본다.
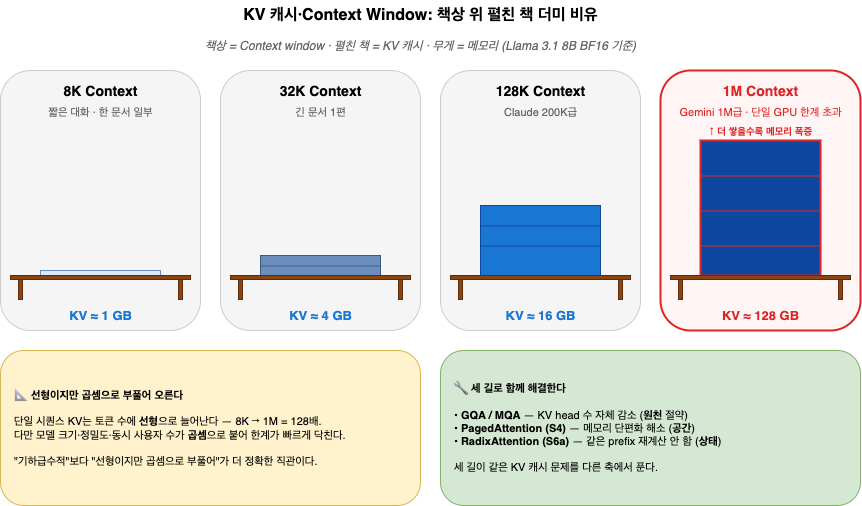
그림 2. 책상 = context window, 펼친 책의 무게 = KV 캐시 메모리, 한 페이지 = 토큰 1개
비유는 여기까지가 깔끔하다. 다음은 이걸 토큰당 KB 단위 숫자로 옮겨보는 내용이다.
모델별 정확 수치 — Llama 3.1 8B/70B 컨텍스트별 표
KV 캐시 크기는 닫힌 공식으로 계산된다. NVIDIA Technical Blog·Lyceum·Morph가 동일하게 인용하는 표준 공식은 다음과 같다.
KV 캐시 (bytes) = 2 × num_layers × num_kv_heads × head_dim × seq_len × dtype_bytes
여기서 2는 K와 V 두 텐서, num_layers는 트랜스포머 블록 수, num_kv_heads는 GQA 이후 KV head 수, head_dim은 헤드 차원, seq_len은 컨텍스트 토큰 수, dtype_bytes는 정밀도 바이트(BF16/FP16 = 2, FP8 = 1)다. Llama 3.1 8B는 HuggingFace config.json에 num_hidden_layers=32, num_key_value_heads=8, hidden_size=4096, num_attention_heads=32로 박혀 있다. head_dim은 4096/32 = 128. 토큰 1개당 KV 캐시는 2 × 32 × 8 × 128 × 2 = 131,072 bytes, 128 KB다.
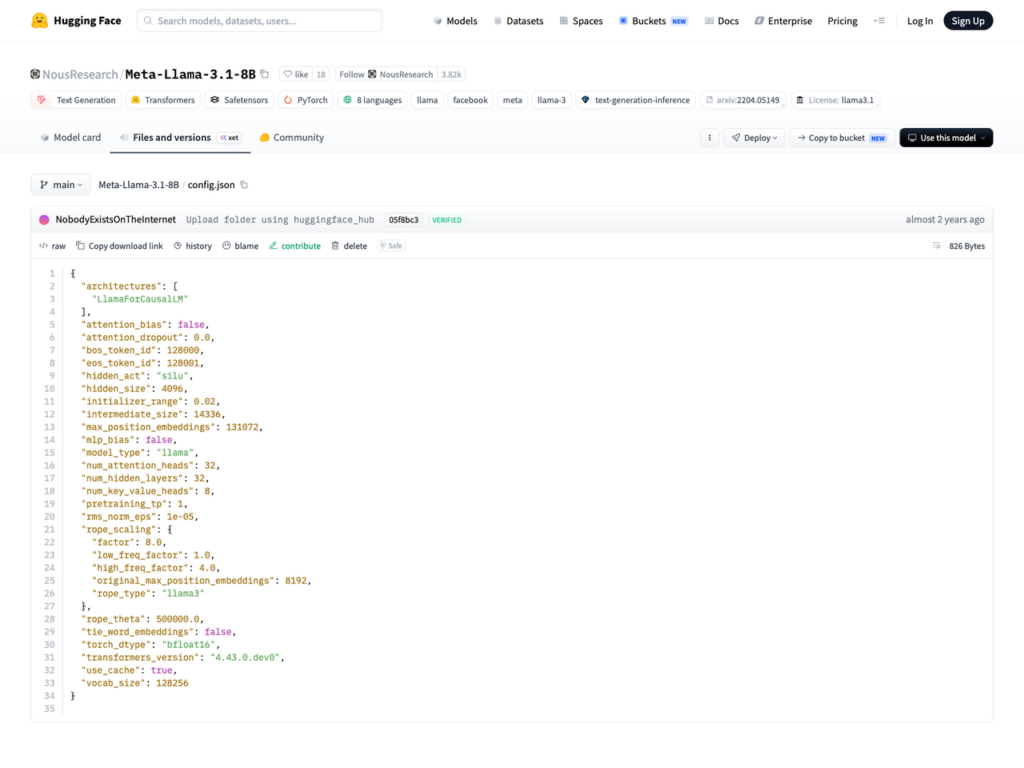
그림 3. Llama 3.1 8B config.json — num_hidden_layers=32, num_key_value_heads=8
여기에 컨텍스트 토큰 수를 곱하면 모델별 KV 캐시가 나온다. 단일 시퀀스(batch=1) 기준이다.
| Context | Llama 3.1 8B (128 KB/token) | Llama 3.1 70B (320 KB/token) |
|---|---|---|
| 8K | 1.0 GB | 2.5 GB |
| 32K | 4.0 GB | 10 GB |
| 128K | 16 GB | 40 GB |
| 1M | 128 GB | 320 GB |
표만 보면 “지수적으로 늘어난다”고 적고 싶어진다. 정확히는 그렇지 않다. 단일 시퀀스의 KV 캐시 자체는 토큰 수에 선형으로 늘어난다. 다만 모델 크기(8B → 70B), 정밀도, 동시 사용자 수가 곱셈으로 붙으면서 GPU 한 장의 한계가 빠르게 닥친다. “기하급수적”보다는 “선형이지만 곱셈으로 부풀어 오른다”가 더 정확하다.
숫자로 보면 분명하다. 70B를 1M로 돌리면 KV만 320 GB라 H100 80GB 한 장에 KV조차 못 들어가고, 가중치(BF16 약 140 GB)까지 합치면 H100 4~5장에 나눠 담아야 한다. 8B도 1M이면 KV 128 GB로 80GB 한계를 넘는다.
GQA가 없었다면 더 무거웠다
표의 무게는 Llama 3.1이 GQA(grouped-query attention)를 쓴 결과다. num_key_value_heads가 query head 수(8B는 32, 70B는 64)보다 작아서(둘 다 8) KV 캐시가 줄어 있다. MHA였다면 8B는 토큰당 512 KB로 4배, 70B는 토큰당 2.5 MB로 8배 더 컸을 거다. 비교 대상을 빼고 “GQA는 8배 절약”이라고만 적으면 8B는 4배라 모순처럼 보이는데 둘 다 맞는 숫자다. GQA는 Ainslie 외 EMNLP 2023이 제안해 Llama 2 70B(2023-07)에서 처음 채택됐고 Llama 3부터 전 사이즈로 통일됐다.
API 가격 임계점 — Gemini 2.5 Pro와 Claude 시점 차
메모리 수치를 가격에 연결할 차례다. 가장 깨끗하게 임계점이 보이는 모델이 Gemini 2.5 Pro다. Google AI 공식 pricing은 input을 ≤200K 구간 $1.25/MTok, >200K 구간 $2.50/MTok(정확히 2배), output은 ≤200K $10/MTok, >200K $15/MTok(1.5배)으로 적는다. 같은 모델인데 200K 라인 하나를 기준으로 단가가 갈린다.
2024 vs 2026 — Claude 200K 임계점의 시점 차
시점 상황 2024-08 ~ 2025 Claude Sonnet 4·4.5, 200K 초과 시 input $3→$6 (2배), output $15→$22.50 (1.5배). 1M 베타·Tier 4+ 한정 2026-04 이후 (현재) Opus 4.8 · 4.7 · 4.6 · Sonnet 4.6은 1M까지 standard pricing. 임계점 사라짐. 공식 docs가 “900k-token 요청도 9k-token 요청과 같은 per-token rate로 청구된다”고 적는다 (Anthropic 모델 버전은 빈번하게 갱신되니 docs 직접 확인 권장) 차이 글이 인용되는 시점에 따라 다르다. 2024 시점에 적힌 글이 그대로 2026까지 돌아다니면서 “Claude 200K = 2배”가 굳어진 모양새다 그러니까 “Claude 200K부터 2배”를 검색에서 본 적이 있다면 그건 2024 시점의 사실이다. 2026 현재 Claude 신모델 라인에서는 그 임계점이 사라졌다. 임계점이 여전히 명시적으로 살아 있는 모델은 지금은 Gemini 2.5 Pro 쪽이다.
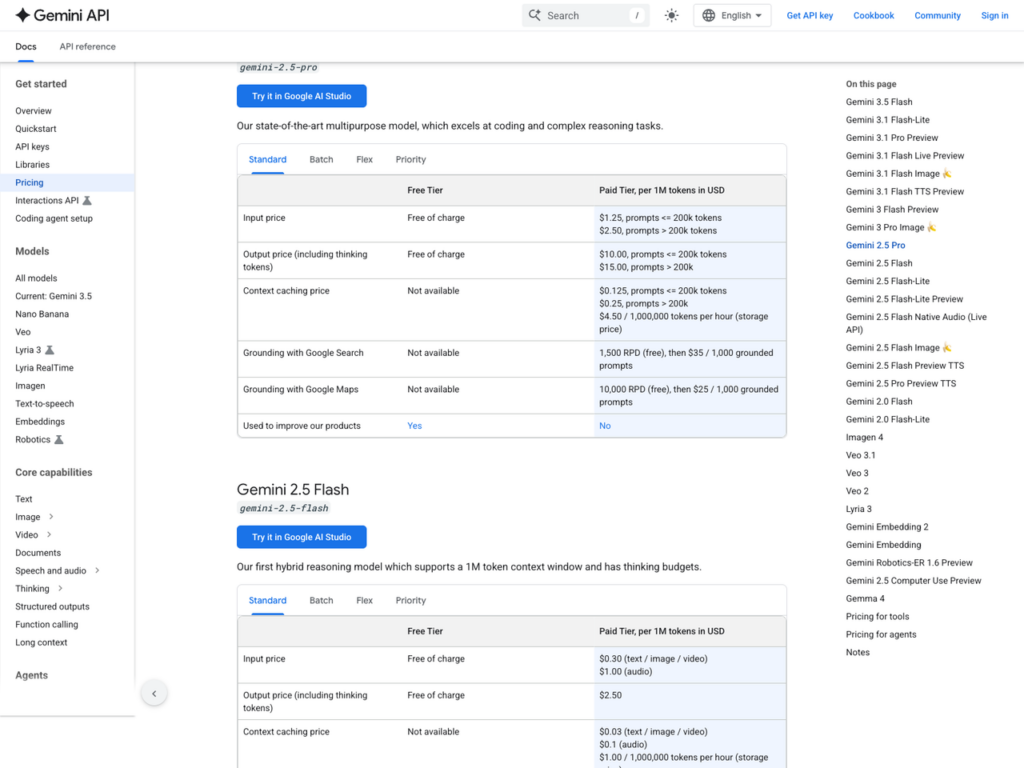
그림 4. Gemini 2.5 Pro의 200K 임계점 — input 2배, output 1.5배
가격 얘기에서 자주 보이는 단정이 하나 더 있다. 인터넷에서 “1M 컨텍스트는 1000배 비싸진다” 같은 문장을 종종 본다. 원전을 못 찾았다. 한국어·영어 검색 어디에도, arxiv·공식 pricing 어디에도 1000배라는 단일 출처가 잡히지 않는다. 가장 가까운 정량 인용은 Yao Fu(2024)가 7B 모델 1M 토큰 KV가 100GB+ VRAM을 요구한다고 적는 정도다. 그래서 여기서는 1000배는 빼고 검증되는 숫자만 적었다 — Llama 3.1 8B 8K→1M KV가 1GB→128GB로 128배, Gemini 2.5 Pro 200K 초과 input 2배.
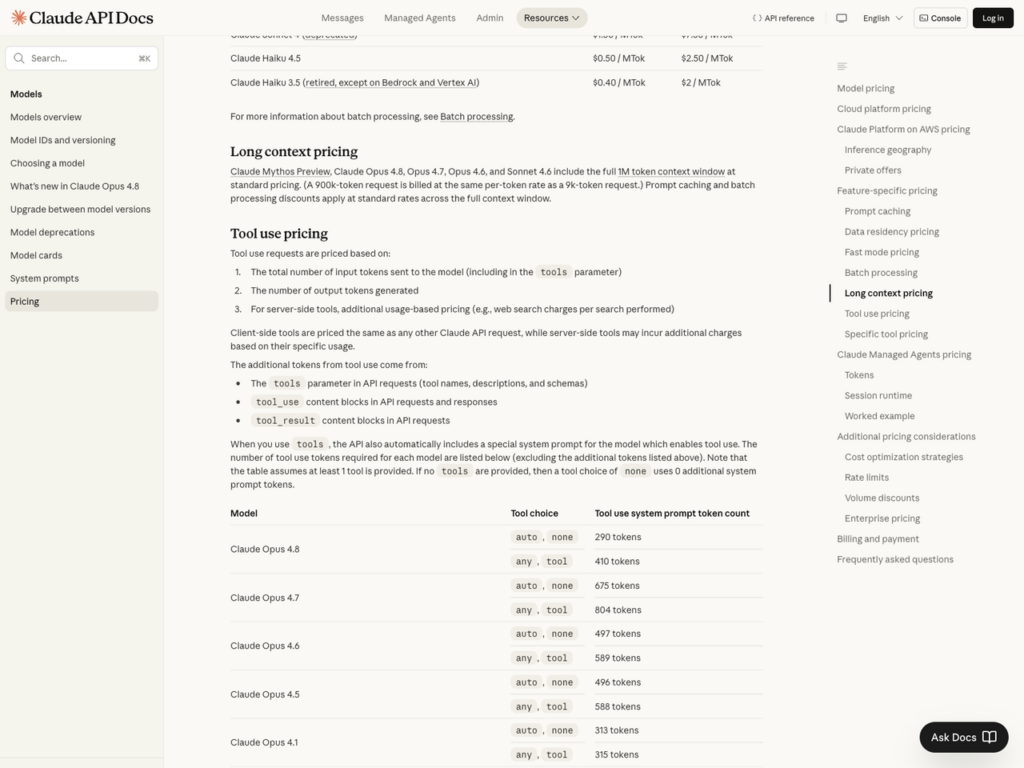
그림 5. Anthropic 공식 docs — Opus 4.8·4.7·4.6·Sonnet 4.6은 1M까지 standard pricing
200K·1M 임계점은 마법이 아니라 H100 80GB 한 장이 KV를 더 들 수 없는 지점이 가격에 비친 모양새다. 그 너머는 GPU 여러 장과 더 복잡한 인프라가 붙어야 하니 단가가 갈린다.
세 길의 정리 — GQA · PagedAttention · RadixAttention
여기까지 보면 KV 캐시는 한 문제, 세 길이 있다.
| 길 | 차원 | 무엇을 줄이나 | 1차 출처 |
|---|---|---|---|
| GQA / MQA | 원천 (KV head 수 자체) | KV head 수를 query head보다 줄여 한 페이지의 무게 자체 감소 | Ainslie EMNLP 2023 / Shazeer 2019 |
| PagedAttention | 공간 (메모리 단편화) | 연속 메모리 예약을 block 단위로 흩어 담아 단편화 해소 | Kwon SOSP 2023 · vLLM 원리 글 |
| RadixAttention | 상태 (계산 중복) | 같은 prefix는 KV 캐시 재사용 (radix tree) | Zheng NeurIPS 2024 · SGLang 원리 글 |
셋은 경쟁이 아니라 다른 축의 답이다. GQA는 한 페이지의 무게 자체를 줄이고, PagedAttention은 책상 위 책 배치의 빈틈을 줄이고, RadixAttention은 같은 첫 장을 두 번 펼치지 않는다. vLLM·SGLang 같은 서빙 엔진은 GQA 모델 위에서 두 기법을 같이 쓴다 — 같은 진앙에 세 약이 다른 축으로 붙는 구조다.
그래서 긴 컨텍스트는 어떻게 다루나
표를 다시 보면 “내 모델 + 내 컨텍스트 = KV 몇 GB”가 머릿속으로 계산된다. 로컬은 그 숫자가 가용 VRAM·통합 메모리를 안 넘어야 하고, API는 컨텍스트 임계점·prompt caching 단가가 곧 비용으로 이어진다. M3 Pro 36GB는 Llama 3.1 8B BF16(16GB) + 32K KV 4GB = 약 20GB로 여유가 있지만, 128K까지 가면 합 32GB로 빠듯해진다. RTX 2070 8GB는 8B BF16 자체가 VRAM을 넘어서 Q4 양자화 + 짧은 컨텍스트 조합만 현실적이다.
API는 또 다른 절약 방법이 있다. Anthropic·Google의 prompt caching·context caching이 반복되는 prefix의 재청구를 일부 흡수한다 — Claude API 비용 가이드에서 캐시 단가와 배치 할인을 정리해뒀다.
자주 묻는 질문
Q1. KV 캐시가 정확히 뭔가요? 트랜스포머가 매 토큰의 key·value 벡터를 메모리에 저장해 다음 토큰을 만들 때 재사용하는 자료구조다. 비유로는 책상 위에 펼쳐둔 책 더미 — 한 페이지는 한 토큰, 책상 크기가 컨텍스트 윈도우다.
Q2. 왜 긴 컨텍스트가 빠르게 비싸지나요? KV 캐시가 토큰 수에 선형으로 늘고, 거기에 모델 크기·정밀도·동시 사용자 수가 곱셈으로 붙어 GPU 한 장의 메모리 한계가 빠르게 닥치기 때문이다. 200K·1M 임계점은 그 한계가 가격에 비친 자리다.
Q3. Claude 200K랑 Gemini 1M, 가격은 똑같이 오르나요? 시점·모델마다 다르다. 2026 현재 명시적 임계점은 Gemini 2.5 Pro의 200K 초과 input 2배·output 1.5배. Claude는 2024~2025 시점엔 Sonnet 4·4.5 200K 초과 2배가 있었지만 2026 현재 Opus 4.8·4.7·4.6·Sonnet 4.6은 1M까지 standard pricing이다.
Q4. GQA가 KV 캐시를 얼마나 아끼나요? 비교 대상을 명시해야 한다. Llama 3.1 8B 기준 4배, 70B 기준 8배 — MHA로 가정한 경우 대비다. MQA로 가면 한 단계 더 줄지만 품질이 같이 떨어지는 trade-off가 있어 Llama 라인은 GQA를 채택했다.
Q5. “1M 컨텍스트는 1000배 비싸진다”는 사실인가요? 원전을 못 찾아 여기서는 다루지 않았다. 검증되는 가까운 정량 인용은 Yao Fu 논문이 짚는 “7B 모델 1M 토큰 KV가 100GB+ VRAM” 정도다.
Q6. 8GB GPU(예: RTX 2070)에서 8K context를 돌릴 수 있나요?
8B 모델 BF16 자체가 16GB라 VRAM을 넘는다. Q4 양자화(45GB) + 짧은 컨텍스트(4K8K)에선 가능하다. 긴 컨텍스트 자체는 8GB 단일 GPU에선 어렵다.
Q7. PagedAttention·RadixAttention·GQA는 어떻게 다른가요? 같은 KV 캐시 문제를 다른 축에서 푼다. GQA는 한 토큰의 KV 크기 자체를 줄이고, PagedAttention은 메모리 단편화를 줄이고, RadixAttention은 같은 prefix를 두 번 계산하지 않는다. 셋은 같이 쓰는 약이다.
정리 — KV 캐시는 마법이 아니라 책상 위 무게다
KV 캐시는 마법이 아니라 책상 위에 펼쳐둔 책의 무게다. 한 토큰을 더할 때마다 무게가 선형으로 늘고, 모델 크기·정밀도·동시 사용자가 곱해지면 GPU 한 장의 한계가 빠르게 닥친다. Claude 200K·Gemini 1M에서 가격이 갑자기 오르는 임계점은 그 무게가 H100 80GB 한 장의 물리 한계를 넘는 지점이다. PagedAttention·RadixAttention·GQA는 그 무게를 줄이는 세 길이고 본 시리즈에서 한 글씩 다뤘다. 원리를 알면 “1M 1000배”라는 숫자에 휘둘리지 않게 된다 — 이 글에서 풀고 싶었던 한 줄이다.
관련 글
- vLLM은 왜 빠른가 — PagedAttention을 OS 페이징으로 이해하기 — 이 글의 짝꿍. 공간 차원(메모리 단편화)으로 KV 캐시 문제를 푼 길.
- SGLang은 왜 빠른가 — RadixAttention과 prefix 공유의 직관 — 이 글의 짝꿍. 상태 차원(prefix 재사용)으로 KV 캐시 문제를 푼 길.
- Claude API 비용 완벽 가이드 2026 — 위 글이 짚은 가격 임계점의 실전 비용 가이드. 200K·prompt caching 맥락.
- Ollama로 M3 Pro 맥북에 로컬 LLM 띄우기 — 30분 실측 가이드 — 로컬 환경에서 KV 캐시 무게를 직접 느끼는 가장 단순한 출발점.
- M3 Pro에서 vLLM 돌려보기 — Mac 3경로와 솔직한 한계 (2026) — 위 vLLM 짝꿍 글의 실측편. 책상 비유의 GB 숫자가 실제 Mac에서 어떻게 도는지.
참고 자료
- Attention is All You Need — Vaswani et al., arXiv:1706.03762 — Transformer·멀티헤드 어텐션 K·V 원전
- Challenges in Deploying Long-Context Transformers — Yao Fu, arXiv:2405.08944 — “KV 캐시가 긴 컨텍스트 어려움의 단일 원인”이라는 학술 뼈대. 7B 모델 1M 토큰 KV 100GB+ 인용
- GQA: Training Generalized Multi-Query Transformer Models — Ainslie et al., arXiv:2305.13245 (EMNLP 2023) — GQA 원논문. 4·8배 절약 출처
- Fast Transformer Decoding — Shazeer, arXiv:1911.02150 — MQA 원논문
- The Llama 3 Herd of Models — arXiv:2407.21783 — Llama 3.1 공식 논문. 128K context·GQA 통일
- Mastering LLM Techniques: Inference Optimization — NVIDIA Technical Blog — KV 캐시 공식 1차 정리
- NousResearch/Meta-Llama-3.1-8B config.json — num_layers·num_kv_heads·head_dim 직접 인용
- Anthropic Pricing — platform.claude.com — Opus 4.8·4.7·4.6·Sonnet 4.6 1M까지 standard pricing 공식 명시
- Anthropic Context Windows — platform.claude.com — “working memory” 표현. 책상 비유 정합 근거
- Gemini API Pricing — Google AI — Gemini 2.5 Pro 200K 임계점 정확 인용
- PagedAttention — Kwon et al., arXiv:2309.06180 (SOSP 2023) — vLLM PagedAttention 원논문
- SGLang RadixAttention — Zheng et al., arXiv:2312.07104 (NeurIPS 2024) — SGLang RadixAttention 원논문