로컬 LLM 처리량 얘기에서 vLLM을 만난 다음 줄에 SGLang이 있다. “최대 6.4배 빠르다”는 상투구가 됐는데, 정작 “왜 빠른가”를 한 문장으로 답해보라면 막힌다. 나도 그랬다. 그래서 공식 자료들을 따라가며 그 핵심을 도서관 책장 정리 비유로 다시 풀어봤다. 지난 글에서 vLLM이 OS 페이징을 KV 캐시에 가져왔다는 이야기를 했는데, SGLang은 같은 문제를 다른 축에서 푼 한 쌍이다. 결론부터 말하면 SGLang의 빠름은 마법이 아니라 같은 prefix로 시작하는 책을 같은 책장에 모아두는, 잘 정리된 도서관의 아이디어다.
그림 1. SGLang 공식 문서 첫 화면
TL;DR
- SGLang은 LMSYS(UC 버클리 Zheng et al.)가 NeurIPS 2024에서 발표한 LLM 서빙 프레임워크. 핵심은 RadixAttention — 접두사 트리(radix tree)로 KV 캐시를 공유하는 알고리즘이다.
- CoT·multi-turn 채팅·few-shot·RAG처럼 같은 prefix가 반복되는 워크로드에서 prefix를 재계산하지 않아 처리량을 끌어올린다. Chatbot Arena 실측 cache hit이 LLaVA-Next-34B 52.4%·Vicuna-33B 74.1%였다 (SGLang 논문).
- 논문 abstract 기준 최대 6.4배 throughput — vs Guidance·vLLM·LMQL·TGI 여러 워크로드의 최댓값(Llama-7B A10G·Mixtral-8x7B). LMSYS 블로그(좁은 범위)는 “최대 5배”로 적었는데 같은 연구를 다른 범위에서 본 수치라 서로 모순이 아니다.
- PagedAttention과는 다른 축의 최적화라 SGLang은 둘을 같이 쓴다. 2025~2026년 vLLM도 APC(Automatic Prefix Caching) 를 도입해 prefix 공유는 두 진영 공통 자산이 됐고, SGLang의 차별은 그 이상의 구조(CFSM·Frontend DSL)로 이동했다.
SGLang이란? 왜 다들 SGLang을 말하나
SGLang은 LMSYS(UC 버클리, vLLM·Chatbot Arena와 같은 그룹)의 Lianmin Zheng 외가 arXiv:2312.07104 — NeurIPS 2024에서 발표한 LLM 서빙 프레임워크다. 2026년 5월 현재 GitHub 28.7k stars, xAI(Grok)·NVIDIA·AMD·LinkedIn·Cursor 등이 운영에 채택했다.
vLLM이 메모리 단편화를 줄여 더 많은 요청을 동시에 처리하는 길이었다면, SGLang은 같은 prefix를 두 번 계산하지 않는 다른 길이다. 둘은 경쟁이 아니라 짝이고, SGLang은 두 기법을 같이 쓴다.
같은 prefix를 매번 다시 계산하는 낭비 — 무엇이 반복되나
KV 캐시를 짧게 짚으면 — LLM은 토큰을 하나씩 생성하면서 앞 토큰의 key/value 벡터를 재사용한다. 매번 다시 계산하면 느리니 메모리에 저장해둔다.
운영 워크로드를 들여다보면 한 가지가 눈에 띈다. system prompt, few-shot 예시, 대화 이력, RAG 컨텍스트가 요청마다 반복된다. 기존 시스템은 이 반복되는 prefix를 매 요청마다 처음부터 다시 KV로 계산한다 — 캐시는 한 요청 안에서만 재사용되고 다음 요청이 오면 사라진다. SGLang 논문은 이 낭비가 특히 큰 4가지를 짚는다 — Few-shot learning, Self-consistency·CoT, Multi-turn chat, Tree-of-thought.
처리량 한계가 메모리에 있다면 vLLM의 PagedAttention이 답이지만, 한계가 같은 prefix를 또 계산하는 데 있다면 다른 길이 필요하다. 그 길이 RadixAttention이다.
RadixAttention 직관 — 도서관 책장 정리 비유
여기가 글의 핵심이다. PagedAttention을 OS 페이징으로 풀었듯, RadixAttention은 도서관 책장 비유로 풀린다.
일반 도서관을 떠올려보자. 책이 입고 순서대로 아무 책장에 꽂힌다. “김”으로 시작하는 책을 찾으려면 처음부터 뒤져야 한다. 기존 KV 캐시가 딱 이 모양이다 — 같은 prefix로 시작하는 시퀀스가 들어와도 이전 결과를 찾을 길이 없으니 처음부터 계산한다.
이제 잘 정리된 도서관을 그려보자. 같은 첫 글자로 시작하는 책은 같은 책장에, 같은 두 글자는 같은 칸에, 같은 세 글자는 같은 선반에 둔다. 트리처럼 가지치기로 분류되는 구조다. prefix가 같은 시퀀스가 들어오면 가장 긴 매칭 칸까지 그대로 재사용하고, 새 토큰만 그 가지 끝에 추가하면 된다.
이 트리가 radix tree(접두사 트리) 다. 일반 trie와 다른 점은 간선에 단일 문자가 아니라 가변 길이 시퀀스가 라벨로 붙는다는 것 — 한 칸에 여러 글자 묶음이 들어간다고 생각하면 된다. KV 노드 메타는 CPU, 실제 KV 텐서는 GPU의 paged layout(토큰 1개당 1 page)에 둔다. PagedAttention의 메모리 구조 위에 RadixAttention의 prefix 공유 레이어가 얹히는 구조다.
동작은 단순하다. 새 요청이 오면 스케줄러가 트리를 순회해 가장 긴 매칭 prefix까지 재사용하고, 신규 토큰만 계산해 가지 끝에 새 노드를 매단다. 자리가 부족하면 가장 오래 안 본 책부터 뺀다 — LRU 기반 eviction(리프 노드부터, reference count 0 우선). 트리 관리 패널티는 작다. LMSYS 블로그는 ShareGPT 측정 오버헤드 0.3% 미만이라고 적는다 — cache hit이 없어도 손해가 거의 없고, hit이 있으면 그만큼 이득이다.
비유를 하나 더 보태면, 멀티턴 채팅은 “회사 양식 템플릿”에 가깝다 — 표지·머리말·정형 문구를 매번 새로 쓰지 않고 양식을 재사용한다.
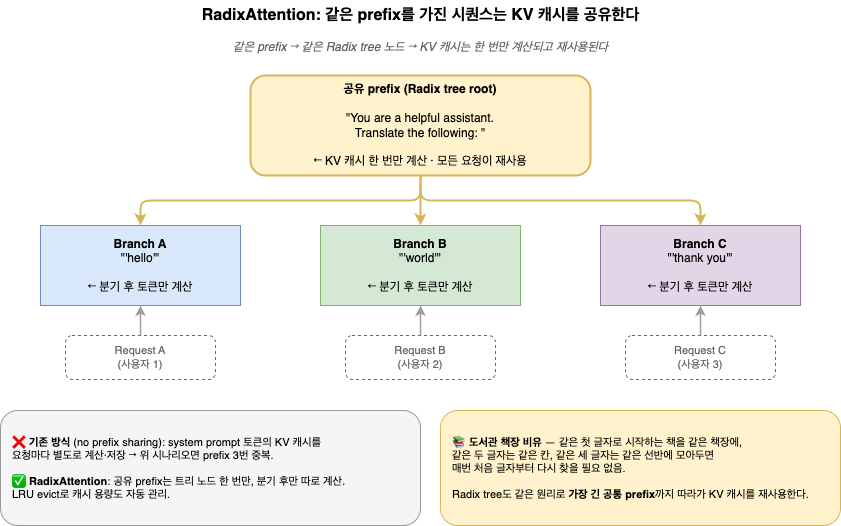
그림 2. RadixAttention의 radix tree — 같은 prefix까지는 재사용, 새 토큰만 새 가지
PagedAttention과 RadixAttention — 공간 vs 상태
vLLM 글을 읽은 사람이 가장 궁금해할 질문에 답할 차례다.
PagedAttention이 공간(메모리)을 아끼고, RadixAttention은 상태(계산)를 아낀다.
두 기법은 서로 다른 영역을 건드리니 같이 쓸 수 있다. LMSYS 블로그 원문이 명시한다 — “RadixAttention is compatible with existing techniques like continuous batching and paged attention.” SGLang 런타임은 paged layout 위에 RadixAttention의 prefix 공유 레이어를 얹는다. 같이 쓴다.
그래서 SGLang vs vLLM은 “어느 게 더 빠른가”가 아니라 “어느 워크로드냐”의 문제다. 그런데 여기서 한 가지 짚고 가야 한다.
2024 vs 2026 — vLLM APC 도입의 진실
시점 상황 2024 초 SGLang의 RadixAttention 발표 직후. vLLM은 prefix caching 미보유. 워크로드에 따라 RadixAttention 우위 명확 2025~2026 vLLM이 APC(Automatic Prefix Caching) 도입. vLLM design docs가 본인 입으로 “this eviction policy effectively implements the exact policy as in RadixAttention when applied to models with full attention“이라고 적는다 — RadixAttention의 정책과 사실상 동등 (full attention 모델 한정) 차이 SGLang은 token-level radix tree, vLLM APC는 block-level hash matching. 매칭 단위와 자료구조가 다르고, 워크로드에 따라 격차가 다르게 나타난다 정리하면, prefix 공유 자체는 두 진영의 공통 자산이 됐다. SGLang의 차별은 그 이상의 구조(아래에서 짧게 볼 Compressed FSM·Frontend DSL)로 이동했다. 이 시점 차를 모르면 “SGLang이 prefix caching의 유일한 답”이라는 인상을 받기 쉬운데, 그건 2024 시점에 적힌 글이 그대로 전해진 결과다.
“최대 6.4배”의 정확한 비교 대상
SGLang 논문 abstract는 이렇게 적는다 — “SGLang achieves up to 6.4× higher throughput compared to state-of-the-art inference systems on various large language and multi-modal models on tasks including agent control, logical reasoning, few-shot learning benchmarks, JSON decoding, retrieval-augmented generation pipelines, and multi-turn chat.” 한 문장에 비교 상대·모델·워크로드·”최댓값” 정보가 모두 들어 있다. 그래서 “6.4배 빠르다”만 따로 떼면 비교 상대·모델·워크로드가 사라진 숫자가 된다.
수치 정직 박스 — 같은 SGLang의 여러 숫자
수치 무엇 대비 무엇 조건 · 출처 최대 6.4배 throughput SGLang vs Guidance·vLLM·LMQL·HuggingFace TGI Llama-7B(A10G)·Mixtral-8x7B, 여러 워크로드의 최댓값 (arXiv:2312.07104 abstract) 최대 5배 throughput SGLang vs Guidance v0.1.8, vLLM v0.2.5, TGI v1.3.0 Llama-7B/Mixtral, A10G, MMLU·HellaSwag·ReAct·ToT (좁은 범위) (LMSYS Blog 2024-01-17) 최대 2.5배 throughput (구조화 출력) SGLang compressed FSM (jump-forward) vs Outlines+vLLM v0.2.7, Guidance+llama.cpp v0.2.38 Llama-7B, 정보 추출·JSON 디코딩 (LMSYS Blog 2024-02-05) cache hit 52.4% / 74.1% RadixAttention 실측 (LLaVA-Next-34B / Vicuna-33B) Chatbot Arena 프로덕션 (SGLang 논문) 같은 SGLang에 대한 다른 숫자가 모순이 아닌 이유는 비교 상대와 워크로드 범위가 다르기 때문이다. S4에서 본 vLLM의 “24배 vs 2~4배”와 같은 패턴.
참고로 “SGLang structured generation 최대 22배”라는 수치를 인터넷에서 종종 본다. 그런데 원전을 못 찾았다. SGLang 논문·LMSYS 블로그·GitHub README·NeurIPS Proceedings를 다 훑어봐도 22배가 어디서 나온 수치인지 짚을 수 없었다. 가장 가까운 검증 가능 수치는 위 표의 CFSM 2~2.5배(vs Outlines+vLLM·Guidance+llama.cpp)이고, xgrammar 통합 이후 JSON 디코딩 3~10배가 LMSYS 트윗 2024-11에서 확인된다. 그래서 본 글에서는 22배는 빼고 위 표의 수치만 적었다.
Compressed FSM과 Frontend DSL — 한 줄로
SGLang의 차별이 RadixAttention “그 이상”으로 이동했다고 했으니, 그 위가 무엇인지 짧게 짚는다.
Compressed FSM(CFSM) — JSON schema·정규식으로 출력을 강제하는 constrained decoding. schema → regex → FSM 변환 후 “토큰 선택지가 단 하나뿐”인 구간을 찾아 여러 토큰을 한 번에 prefill 처리한다(jump-forward). 구조화 출력이 자유 생성보다 빨라지는 경우가 생기는 이유다 — LMSYS 블로그 참조.
Frontend DSL — Python 내장 DSL로 prompt 흐름을 함수처럼 표현한다(gen()·select()·fork()). prefix 공유 효과는 vanilla API에서도 자동으로 얻으니, DSL은 여러 단계 prompt 프로그램을 함수처럼 짜는 추가 도구로 보면 된다.
Ollama·vLLM·SGLang — 어느 게 빠른가가 아니라 목적이 다르다
원리를 알고 나면 자주 나오는 질문이 “그럼 셋 중 뭐 쓰지”다. Ollama는 단일 사용자 prototyping의 단순함, vLLM은 다중 요청 처리량의 메모리 효율, SGLang은 prefix가 반복되는 워크로드(챗봇·RAG·에이전트·CoT)의 계산 절약과 jump-forward — 어느 게 빠른가가 아니라 목적이 다르다. SGLang은 vLLM의 대체가 아니라 PagedAttention 위에 RadixAttention을 얹는 조합 관계고, 단일 사용자 로컬에선 Ollama가 더 실용적, 동시 요청이 많은 서버에서 SGLang 이득이 드러난다. 단일 기기 결정 트리는 후속 글(준비 중).
자주 묻는 질문
Q1. SGLang이 vLLM보다 정말 6배 빠른가요? 6.4배는 SGLang 논문 abstract의 vs Guidance·vLLM·LMQL·TGI 여러 워크로드 최댓값(Llama-7B A10G·Mixtral-8x7B)이다. LMSYS 블로그(좁은 범위)에선 5배, 일반 batch 워크로드에선 더 작을 수 있다.
Q2. RadixAttention과 PagedAttention의 차이는 무엇인가요? PagedAttention은 메모리 단편화를 줄여 공간을 아끼고, RadixAttention은 같은 prefix를 두 번 계산하지 않아 상태(계산)를 아낀다. 둘은 서로 다른 축의 최적화라 SGLang은 둘을 같이 쓰고, 2025~2026년 vLLM도 APC로 prefix caching을 흡수했다.
Q3. SGLang은 vLLM을 대체하나요? 꼭 그렇진 않다. prefix 공유 효과가 큰 워크로드(챗봇·RAG·에이전트·CoT)는 SGLang이 강점, 일반 서빙은 vLLM도 충분. 둘 다 OpenAI 호환 API라 엔드포인트만 바꾸면 코드가 그대로 붙는다.
Q4. RadixAttention은 어떤 워크로드에 가장 효과적인가요? system prompt가 반복되는 챗봇, few-shot 예시를 공유하는 분류·추출, CoT 분기, multi-turn 대화처럼 prefix가 반복되는 패턴이다. Chatbot Arena 실측 cache hit이 LLaVA-Next-34B 52.4%·Vicuna-33B 74.1%(SGLang 논문 RadixAttention 실험)였다.
Q5. SGLang의 Compressed FSM이 22배 빠르다는데 사실인가요? 논문·LMSYS·GitHub README를 다 훑어봐도 22배 수치는 못 찾았다. 검증되는 가까운 수치는 CFSM(jump-forward)의 최대 2.5배 throughput·2배 latency 감소 — vs Outlines+vLLM v0.2.7·Guidance+llama.cpp v0.2.38(LMSYS 2024-02-05)이고, xgrammar 통합 후 JSON 디코딩 3~10배가 LMSYS 트윗 2024-11에 보고됐다. 그래서 본 글에서도 22배는 다루지 않았다.
Q6. SGLang을 RTX 2070·M3 Pro 같은 소비자 GPU에서 돌릴 수 있나요? 가능하나 throughput 이득은 동시 요청이 많은 서버 시나리오에서 본격적으로 나타난다. 단일 사용자 로컬은 Ollama·llama.cpp가 더 실용적이고, 결정 트리는 후속 글에서 다룬다.
Q7. SGLang은 Ollama와 어떻게 다른가요? “단일 사용자 = Ollama, 다중 처리량 + prefix 반복 = SGLang”으로 정리하면 헷갈리지 않는다. 어느 게 빠른가가 아니라 목적이 다르다.
정리 — 빠름은 마법이 아니라 책장 정리다
SGLang의 빠름은 트리 한 그루에서 나온다. 같은 prefix로 시작하는 KV를 같은 가지에 모아두고, 새 요청이 오면 가장 긴 매칭 가지까지 재사용한 뒤 새 토큰만 가지를 친다 — 도서관이 잘 정리되면 같은 책을 두 번 찾으러 안 다니듯. PagedAttention과 짝이고, 공간을 아끼는 길과 상태를 아끼는 길은 다른 축이라 같이 쓸 수 있다. 2026년 vLLM도 APC로 같은 방향을 흡수했고, SGLang의 차별은 그 위(CFSM·Frontend DSL)로 옮겨갔다. 원리를 알면 “6.4배”라는 숫자에 휘둘리지 않게 된다. 이 글에서 풀고 싶었던 게 그 한 줄이다.
관련 글
- vLLM은 왜 빠른가 — PagedAttention을 OS 페이징으로 이해하기 — 본 글의 짝꿍. RadixAttention과는 다른 축(공간 차원)의 원리. 본 글의 “PagedAttention vs RadixAttention” 박스가 직접 참조한 글이다.
- M3 Pro에서 vLLM 돌려보기 — Mac 3경로와 솔직한 한계 (2026) — 짝꿍 글의 실측편. 원리를 알았으니 실제 맥에서 어떻게 도는지 보고 싶다면.
- Ollama로 M3 Pro 맥북에 로컬 LLM 띄우기 — 30분 실측 가이드 — “셋 중 뭐 쓰지”의 가장 단순한 출발점. “단일 사용자 = Ollama” 맥락.
- (준비 중) Mac·RTX 2070에서 SGLang 결정 트리 — 본 글의 실측 짝으로 이어질 후속 글.
참고 자료
- SGLang: Efficient Execution of Structured Language Model Programs — arXiv:2312.07104 (NeurIPS 2024) — RadixAttention·CFSM 원논문. 6.4배·cache hit 52.4%·74.1% 출처
- KV 캐시가 뭐길래 — 긴 컨텍스트가 빠르게 비싸지는 이유 — 본 글이 다룬 RadixAttention의 진앙. PagedAttention(공간)·RadixAttention(상태)이 풀려고 한 KV 캐시 자체를 책상 비유로 푼 학습 시리즈 뿌리 글. Claude 200K·Gemini 1M 가격 임계점까지.
- Fast and Expressive LLM Inference with RadixAttention and SGLang — LMSYS Blog (2024-01-17) — RadixAttention 도입 글. 5배(좁은 범위) 출처, “compatible with paged attention” 인용
- Fast JSON Decoding for Local LLMs with Compressed Finite State Machine — LMSYS Blog (2024-02-05) — CFSM 도입 글. 2.5배·2배 출처
- vLLM Automatic Prefix Caching — design docs — vLLM이 RadixAttention 정책을 흡수했음을 본인 문서에 명시한 1차 근거 (“when applied to models with full attention”)
- vLLM Automatic Prefix Caching — 사용 문서(latest) — APC 사용·설정 소개 페이지
- SGLang GitHub Repository — 최신 버전·운영 채택 현황(2026-05 기준 28.7k stars, xAI·NVIDIA·AMD·Cursor 등)
- PagedAttention 원논문 — arXiv:2309.06180 (SOSP 2023) — 짝꿍 글 S4의 1차 출처. 본 글에선 비교 컨텍스트로 1회 참조