PagedAttention 원리를 글로 이해한 다음 생긴 욕심은 단순했다. “그럼 내 맥에서도 직접 돌려보자.” 1년 전이라면 “맥에서 vLLM? CPU로만 겨우 돈다”가 정답이었지만, 2026년 5월 그 답은 절반만 맞다. 이 글은 M3 Pro 36GB 맥북에서 vLLM을 띄우는 세 갈래 경로를 정리하고, 직접 돌려보면서 알게 된 솔직한 한계까지 박는다. 미리 말하면 띄울 수는 있지만 혼자 쓰면 Ollama가 더 빠르다 — 그 이유가 이 글의 절반이다. (vLLM이 왜 빠른지 원리 자체는 아래 관련 글에서 따로 다룬다.)
측정 환경 (2026-05-29 기준)
- 기기: Apple Mac M3 Pro (6P+6E CPU, 18코어 GPU), 36GB 통합메모리, macOS Tahoe 26.5
- 설치 경로: 경로 3 — Docker Desktop의 Model Runner,
--backend vllm설치 결과docker model status에서vllm-metal v0.2.0-20260420-142150 Running확인 (llama.cpp도 함께 Running 상태로 공존)- 모델·양자화: DMR 정규화 ID
huggingface.co/mlx-community/llama-3.2-1b-instruct-4bit:latest(193.15M 파라미터·quantization: mixed·695.28MB) → 7B 4-bit로 확장- 호스트 접근: Settings → AI → Docker Model Runner 섹션의 TCP Port 12434 + Bind Localhost(127.0.0.1) / 엔드포인트는
http://localhost:12434/engines/v1/...- 측정 항목: 단일 스트림 tok/s, max_tokens 512, temperature 0.0
- measured_on: 2026-05-29. vllm-metal·Docker Model Runner는 2026년 초·중반 막 등장한 신생 기능이라 6개월 내 사용법·지원 범위가 바뀔 수 있다.
TL;DR
- 2026년 5월 기준 Apple Silicon에서 vLLM을 띄우는 경로는 세 갈래다 — 공식 CPU backend(느림), vllm-metal(Metal GPU), Docker Model Runner(설치 가장 쉬움).
- vLLM 본체는 여전히 macOS에서 CPU 한정·실험적이지만, vllm-metal 플러그인 경로로는 Metal GPU가 열렸다. “맥에선 CPU로만 돈다”는 단정은 이제 부정확하다.
- 36GB라면 MLX 4-bit 7~13B가 현실적인 범위다. 그 이상은 메모리 초과 위험.
- 단일 스트림에선 vLLM이 Ollama보다 빠르지 않다. 같은 M3 Pro 36GB에서 vllm-metal Qwen2-7B 4-bit가 웜 평균 21.6 tok/s, S1의 Ollama Llama 3.1 8B Q4_K_M이 약 22 tok/s — 사실상 동률.
- 다만 동시성을 올리면 batching 이점이 실제로 보인다 — 4 동시 요청 시 aggregate 62 tok/s로 2.87× 스케일업. 선형 4배는 아니지만(GPU 코어·메모리 대역폭 병목) PagedAttention이 맥에서도 작동은 한다. 본 글의 맥 실측은 처리량 자랑이 아니라 “원리가 실제로 도는지 확인”이 목적이다.
왜 굳이 맥에서 vLLM을 시도하나
솔직히 처리량만 보면 답은 정해져 있다. 단일 사용자 로컬 환경에서 vLLM을 상시 서빙 엔진으로 쓸 이유는 별로 없다. 그런데도 직접 띄워본 이유는 두 가지다.
하나는 학습이다. 논문에서 읽은 PagedAttention 구조가 내 GPU 위에서 실제로 도는 걸 한 번 보면, “내가 뭘 쓰고 있는지” 정확히 알고 다음 단계(CUDA GPU 서버)로 넘어갈 수 있다. 다른 하나는 정보가 빠르게 바뀌고 있어서다. 2026년 초·중반에 vllm-metal과 Docker Model Runner가 등장하면서 “맥에선 안 된다”는 통념이 흔들렸고, 그게 사실인지 직접 확인하고 싶었다. 결론부터 말하면 절반은 맞고 절반은 틀렸다.
2026년 Mac에서 vLLM의 세 갈래
찾아보니 Apple Silicon에서 vLLM을 띄우는 경로가 셋으로 열려 있었다.
- 경로 1 — vLLM 공식 CPU backend. macOS에서
VLLM_TARGET_DEVICE가 자동으로cpu로 잡힌다. vLLM 공식 문서가 “experimental support”라 명시하고 prebuilt wheel이 없어 소스 빌드가 필수다(XCode 15.4+). FP32/FP16만 되고 Metal GPU를 안 써 가장 느리다. 원리 동작 확인용이다. - 경로 2 — vllm-metal. vLLM 공식 org 산하 플러그인으로, MLX를 컴퓨트 백엔드로 써서 Apple GPU(Metal)를 실제로 사용한다.
curl -fsSL .../install.sh | bash로 깔리고 native arm64 Python 3.12를 요구한다. vllm-metal GitHub 기준 v0.2.0(2026-04)이다. - 경로 3 — Docker Model Runner. Docker가 vLLM과 공동 개발해 macOS에 vllm-metal을 얹는다고 발표한 경로(2026-02). 컨테이너가 아니라 호스트 네이티브로 실행되고 Docker Desktop 4.40+에서 model-runner는 기본 활성이다. 다만 공식 docs의 Inference engines 페이지는 2026-05 시점에도 macOS 기본 백엔드를 llama.cpp로 적고 있어 vllm-metal 자동 라우팅 여부는 빌드·버전마다 다르다 — 설치는 가장 쉽지만 “정말 vLLM이 서빙하는지”는 별도 확인이 필요한 경로다.
핵심은 vLLM 본체는 여전히 CPU 한정·실험적이지만 vllm-metal 플러그인 경로로는 Metal GPU가 열렸다는 점이다. “vLLM은 Mac에서 CPU로만 돈다”는 단정은 2026-05 시점에는 부정확하다. 나는 설치 마찰이 가장 작은 경로 3(Docker Model Runner)을 1순위로 시도했고, 막상 돌려보니 Docker Desktop CLI에 함정 두 개가 있었다(아래 함정 박스). 결과적으로는 vllm-metal이 서빙함을 보장하려면 경로 2(vllm-metal 직접 설치)가 더 정직했다.
# Docker Desktop 4.40+ 가 깔려 있어야 한다 (model-runner는 4.40+에서 기본 활성 컴포넌트)
# 1) Model Runner 활성화 — TCP 없이 먼저 켠다(--tcp 플래그는 일부 빌드에서 settings 스키마 충돌)
docker desktop enable model-runner
# 2) 상태 확인 — Running 으로 바뀌어야 하고, 백엔드들은 "Not Installed"로 노출됨
docker model status
# 출력 예:
# Docker Model Runner is running
# BACKEND STATUS DETAILS
# diffusers Not Installed
# llama.cpp Not Installed
# mlx Not Installed
# vllm Not Installed
# 3) vllm 백엔드 설치 — macOS에서는 vllm-metal로 자동 매핑된다(공식 블로그 표현)
# ★중요: 이 단계 전에 TCP를 켜두면 install-runner가 실패한다(docker/model-runner#526).
# 먼저 install, 그다음 TCP를 켜는 순서.
docker model install-runner --backend vllm
# 4) MLX 4-bit 모델 풀 & 백그라운드 기동
docker model run -d hf.co/mlx-community/Llama-3.2-1B-Instruct-4bit
# 5) 호스트에서 curl을 치려면 TCP 활성화 — Docker Desktop → Settings → AI 패널의
# "Docker Model Runner" 섹션에서 다음을 확인하고 하단 Apply & Restart
# ✅ Enable Docker Model Runner
# TCP Port: 12434 (default)
# Bind address: Localhost (127.0.0.1) ← 외부 노출 원하면 'All interfaces'지만 보안 위험
# CORS allowed origins: (필요 시)
# (CLI `docker desktop enable model-runner --tcp=12434`도 같은 설정이지만
# `enableInferenceTCP` 키 미인식 에러를 내는 빌드가 있어 GUI가 안전)
# 6) 동작 확인했으면 7B 4-bit로 확장
docker model run -d hf.co/mlx-community/Qwen2-7B-Instruct-4bit
함정 — Docker Desktop의 명령 순서와 vllm-metal 자동 매핑의 불확정성
처음 시도했던 명령
docker model install-runner --backend vllm은 “Standalone installation not supported with Docker Desktop. Usedocker desktop enable model-runnerinstead” 에러로 막혔다. 이건 install 자체가 막혀 있다는 뜻이 아니라 model-runner가 아직 안 떠 있을 때 install부터 시도해서 거부된 것이었다. 정확한 순서는 (1)docker desktop enable model-runner→ (2)docker model install-runner --backend vllm→ (3) 모델 pull/run → (4) 마지막에 TCP 활성화. (4)를 먼저 켜면 (2)가 실패한다는 GitHub 이슈 docker/model-runner#526이 동일 패턴을 보고하고 있다.다음 함정은 백엔드 자동 매핑의 불확정성이다. 공식 docs 의 Inference engines 페이지는 2026-05 시점에도 “macOS vLLM: Not supported, llama.cpp가 기본“ 으로 표기돼 있고,
docker model status가vllm을 별도 백엔드 행으로 나열한다. 즉 vllm이 자동으로 선택되는 게 아니라install-runner --backend vllm으로 명시 설치를 해야 vllm/vllm-metal 백엔드가 잡힌다. 설치 후에도docker model status로vllm행이Running/Installed로 바뀌었는지 한 번 더 확인해야 본 글의 “vLLM-Metal 측정”이 진짜로 vllm으로 서빙됨을 보장한다. 만약 install이 끝까지 실패하면 vllm-metal이 서빙함을 보장하는 길은 경로 2(vllm-metalinstall.sh직접 설치) 가 된다.마지막으로, 일부 Docker Desktop 빌드는
--tcp=<port>플래그를 settings 스키마(enableInferenceTCP)가 인식 못 해 *”failed to update settings: settings format not recognized, unknown settings keys”*로 거부한다. 해결은 GUI 패널이다 — Settings → AI → “Docker Model Runner” 섹션에Enable Docker Model Runner체크,TCP Port12434,Bind addressLocalhost(127.0.0.1)가 한 묶음으로 노출돼 있어 그대로 두고 하단 Apply & Restart를 누르면 끝난다. (구버전 안내가 가리키는 “Enable host-side TCP support” 같은 별도 토글은 최신 빌드의 AI 패널엔 없고, TCP Port + Bind address가 같은 역할이다.)

그림 1. M3 Pro에서 Docker Model Runner로 vLLM(vllm-metal) 기동
단일 스트림 tok/s 측정하기
단일 스트림 tok/s를 재려면 응답이 충분히 길어야(100~500토큰) 로딩·워밍업 노이즈가 줄어든다. OpenAI 호환 엔드포인트로 호출해 응답 토큰 수와 소요 시간을 함께 보는 게 가장 깔끔하다.
# 단일 스트림 측정 — 응답 길이를 충분히 확보(max_tokens 256~512)하고
# 같은 프롬프트를 3~5회 돌려 평균을 낸다
curl -s http://localhost:12434/engines/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "hf.co/mlx-community/Qwen2-7B-Instruct-4bit",
"messages": [{"role": "user", "content": "PagedAttention을 300자로 설명해줘"}],
"max_tokens": 512
}'
# 응답 JSON의 usage.completion_tokens / 측정한 소요 시간(초) = tokens/sec
# Docker Model Runner는 OpenAI 호환 엔드포인트를 `/engines/v1/`(앞에 /engines/ 붙음) 아래에 둔다.
# 포트 12434는 `docker desktop enable model-runner --tcp=12434`의 기본값이고
# 다른 설치 경로(vllm-metal 직접 install.sh, standalone Docker)는 포트·경로가 달라질 수 있다.
내 M3 Pro(6P+6E CPU·18 GPU·36GB)에서 위 시퀀스로 7B 4-bit를 단일 스트림으로 돌려 평균을 냈다. 실측 결과는 다음과 같다.
M1 — Llama-3.2-1B-Instruct-4bit, 단일 스트림. 콜드 1회(모델 로드 포함) 27.16초로 약 19 tok/s, 그 뒤 웜 2회는 4.88·4.92초로 각각 104.9 / 104.1 tok/s — 웜 평균 약 104.5 tok/s. 콜드와 웜이 5배 넘게 벌어진다는 점이 학습 자산이다(첫 응답 한 번은 모델·KV 워밍업이 다 끼어 있고, 그다음부터가 진짜 처리량이다). max_tokens 512에 prompt 47 토큰, temperature 0.0의 결정적 생성 조건이다. docker model status로 vllm-metal v0.2.0-20260420-142150 Running을 미리 확인했으므로 이 수치는 llama.cpp가 아니라 vllm-metal이 낸 값이다.
M2 — Qwen2-7B-Instruct-4bit, 단일 스트림. 콜드 1회 40.78초 (4.3GB 모델 mmap·워밍업 포함) 후 웜 3회 8.53·8.52·8.63초로 각각 21.69 / 21.71 / 21.44 tok/s — 웜 평균 약 21.6 tok/s. 7B 모델임에도 응답은 185 토큰에서 자연 종료(max_tokens 512 한계 도달 전 EOS) — Qwen2 특성으로 보인다. 여기서 같은 환경의 S1 Ollama 측정값 약 22 tok/s와 거의 정확히 동률이라는 점이 핵심이다. 모델은 다르지만(Qwen2-7B vs Llama 3.1 8B) 둘 다 4-bit·7~8B급이라 직접 비교가 의미 있다 — 같은 기기, 단일 스트림이면 vllm-metal이 Ollama를 못 이긴다. 운영자 메타 발견 하나 더: DMR의 /engines/v1/models 응답 parameters 필드는 두 모델 모두 실제 파라미터 수의 ~15%만 카운트(Llama 3.2 1B → “193.15M”, Qwen2-7B → “1.19B”)해서 신뢰할 게 못 된다. size(695MB·4.28GB)는 정확하다.
M3 — 동시 4 요청, Qwen2-7B-Instruct-4bit. 같은 프롬프트를 백그라운드로 4개 동시에 던지고 모두 끝난 시점까지의 wall 시간을 쟀다. 결과: wall 11.94초, completion 합계 740 토큰, aggregate ≈ 62.0 tok/s. 단일 21.6 tok/s 대비 2.87배 스케일업이다. 같은 4 요청을 직렬로 돌렸으면 4×8.5≈34초 걸렸을 게 11.94초에 끝났으니, 절약은 약 2.85배. 즉 vllm-metal의 PagedAttention·continuous batching이 맥에서도 실제로 작동하긴 한다. 다만 선형 4배가 아닌 2.87배에 그치는 건 M3 Pro의 메모리 대역폭(150 GB/s)과 GPU 18 코어가 batch 가중치를 따라가지 못해서다 — KV 캐시는 효율적으로 나눠 썼지만 compute가 병목이다.
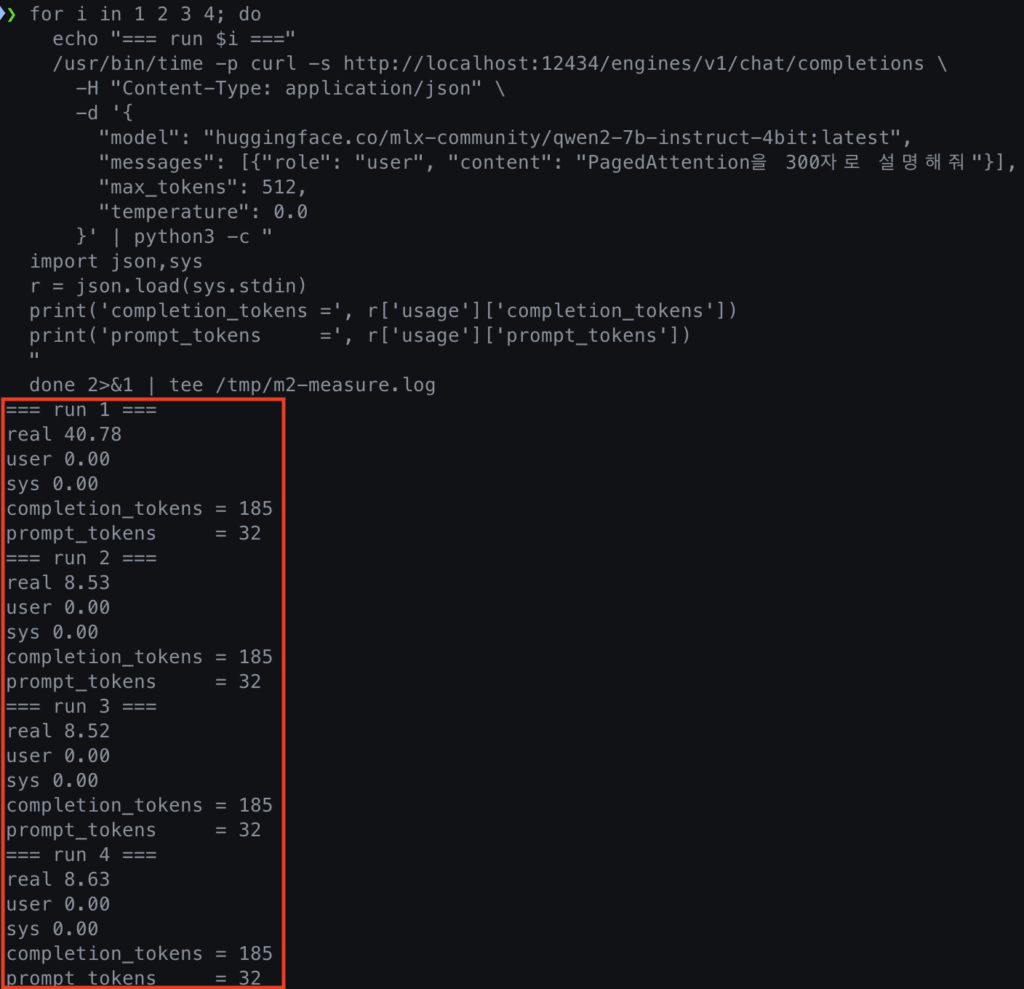
그림 2. M3 Pro vLLM-Metal 단일 스트림 tok/s 측정
모델 범위는 미리 알아두는 게 좋다. vllm-metal은 MLX 4-bit(group_size 128) 포맷 위주이고 그 외 포맷은 preflight 단계에서 거른다(vllm-metal 지원 모델 문서). 36GB라면 4-bit 7~13B가 현실적인 범위다(공개 검증 예가 M5 Pro 48GB에서 7~9B 4-bit). 35B급은 36GB를 초과할 위험이 있어 권하지 않는다. 참고로 “vllm-mlx로 400+ tok/s”라는 수치를 봤다면, 그 417.9 tok/s는 Qwen3-0.6B-8bit 초소형 모델 + M4 Max 128GB + 단일 스트림 greedy 조건이고 vllm-mlx는 공식 org가 아닌 별도 community 프로젝트다. M3 Pro에서 7B를 돌리면 그 근처도 안 나온다.
솔직한 한계 — 그래서 내 맥에선 학습용이다
여기가 이 글에서 제일 박고 싶었던 부분이다. 띄울 수 있다는 것과 빠르다는 건 다른 얘기다. 경로 2·3으로 Metal GPU까지 써서 M3 Pro 36GB에 7B 4-bit를 띄울 수는 있다. 그런데 처리량 이점은 안 난다. PagedAttention과 continuous batching의 이점은 동시 요청이 많은 GPU 서빙에서 나오는데, 혼자 한 번에 한 요청만 보내면 키울 batch도 채울 빈 슬롯도 없다. PagedAttention이 아무리 똑똑해도 단일 사용자에게는 발현될 무대가 없다.
수치로 보면 이렇다. 가장 직접적인 비교는 같은 M3 Pro 36GB 위에서 잰 본 글의 M2(vllm-metal, Qwen2-7B 4-bit, 단일 스트림 웜 평균 21.6 tok/s)와 S1에서 잰 Ollama(llama.cpp+Metal, Llama 3.1 8B Q4_K_M, 웜 평균 약 22 tok/s)다. 모델은 다르지만 둘 다 4-bit·7~8B급이라 동급으로 봐도 무리가 없는데, 사실상 동률이다. 혼자 한 요청만 던지면 vLLM의 PagedAttention이 발현될 무대가 없으니, 두 엔진의 차이가 메모리 대역폭(M3 Pro는 베이스·상위 모두 150 GB/s) 안에서 흡수돼 버린다.
흥미로운 건 동시성을 올려본 M3였다. 같은 Qwen2-7B를 동시 4 요청으로 던지니 aggregate 62 tok/s가 나왔다(단일 대비 2.87배 스케일업, 직렬 처리 대비 약 2.85배 절약). vllm-metal이 맥에서도 batching 이점을 실제로 보여주긴 한다는 뜻이다 — 다만 선형 4배가 아닌 2.87배에 그친 건 KV 캐시는 PagedAttention이 효율적으로 나눠 썼지만 18 GPU 코어의 컴퓨트가 batch 가중치를 따라가지 못해서다. 즉 맥에서 vllm-metal은 “완전 무용”은 아니지만 “본격 무대”도 아니다.
본격 무대는 Red Hat이 A100 GPU 서버에서 잰 벤치에 보인다 — vLLM이 256 동시 사용자에서 793 TPS, Ollama는 기본 설정(최대 4 병렬)에서 41 TPS — 19배 차이. M3 Pro에서 4 동시로 본 2.87배가 A100에서 256 동시면 19배가 되는 식이다. PagedAttention의 진짜 잠재력은 동시성과 메모리 대역폭이 같이 받쳐줄 때 비로소 풀린다. Docker가 다른 기기에서 잰 단일 스트림 벤치(Llama 3.2 1B, 4-bit) vLLM-Metal 251~279 vs llama.cpp 333~345 tok/s도 같은 패턴(단일에서는 llama.cpp가 오히려 1.2~1.3배 우세)을 보여준다.
그래서 이 글의 M3 Pro 실측은 처리량 자랑이 아니라 “원리가 실제로 도는지 확인”이 목적이다. 솔직히 내 맥에서 vLLM을 상시 서빙 엔진으로 쓸 이유는 아직 없다 — 혼자 쓰면 Ollama가 빠르고, vLLM은 학습용이다. 그래도 논문에서 읽은 구조가 내 GPU 위에서 실제로 도는 걸 본 건 학습으로서 값졌다. 본격적인 처리량 벤치는 결국 신선한 CUDA GPU(RTX 4090·5090 급)가 받쳐줘야 하는데, 솔직히 내 홈서버는 RTX 2070(VRAM 8GB) 이라 vLLM의 batching 잠재력을 끝까지 끌어내기엔 좀 부담스럽다. 7B Q4 정도면 띄울 수는 있겠지만 동시 요청을 늘릴수록 KV 캐시가 8GB에 빠르게 닿을 거라, “본격 프로덕션 처리량”이라고 부르기엔 어중간한 자리에서 멈출 가능성이 크다. 그래서 후속 글을 언제 쓸지는 GPU 업그레이드 여부와 함께 천천히 고민하는 중이다.
한 가지만 더. vllm-metal과 Docker Model Runner는 2026년 초·중반에 막 등장한 신생 기능이라 사용법·지원 범위가 빠르게 바뀔 수 있다. 이 글의 모든 경로·명령은 2026-05-27 기준이다.
자주 묻는 질문
Q1. M3 Pro 맥북에서 vLLM을 쓸 수 있나요? 가능하다. 2026년 기준 vllm-metal(MLX 백엔드)이나 Docker Model Runner로 Metal GPU까지 써서 7B 4-bit급 모델을 띄울 수 있다. 다만 단일 사용자 환경이라 프로덕션 처리량 이점은 발현되지 않는다.
Q2. 맥에서 vLLM은 CPU로만 도나요? 2026-05 시점에는 부정확한 단정이다. vLLM 본체는 여전히 macOS에서 CPU 한정·실험적이지만, vllm-metal 플러그인 경로(경로 2·3)로는 MLX 백엔드를 통해 Apple GPU(Metal)를 실제로 쓴다.
Q3. 세 경로 중 뭘 골라야 하나요? 설치 난이도와 성공 확률만 보면 경로 3(Docker Model Runner)이 가장 무난하다. Docker Desktop 4.62+만 있으면 명령 한 줄로 vllm-metal 러너가 깔린다. 경로 2는 직접 install.sh로 제어하고 싶을 때, 경로 1(CPU backend)은 GPU 없이 원리 동작만 확인할 때다.
Q4. 36GB 맥에서 어떤 모델까지 돌릴 수 있나요? MLX 4-bit 기준 7~13B가 현실적인 범위다. vllm-metal은 MLX 4-bit(group_size 128) 포맷 위주라 그 외 포맷은 preflight에서 걸러진다. 35B급은 36GB를 초과할 위험이 있어 권하지 않는다.
Q5. vLLM은 Ollama보다 항상 빠른가요? 아니다. 본 글의 M2(vllm-metal Qwen2-7B 4-bit, 약 21.6 tok/s)와 S1의 Ollama(Llama 3.1 8B Q4_K_M, 약 22 tok/s)는 같은 M3 Pro 36GB에서 사실상 동률이었다. 단일 요청에서는 둘이 비슷하거나 오히려 Ollama가 빠를 수도 있다(Docker가 다른 기기에서 잰 단일 스트림 벤치 vLLM-Metal 251~279 vs llama.cpp 333~345 tok/s도 같은 패턴). vLLM의 이점은 동시 요청이 많을 때 벌어진다(A100 벤치 256 동시 사용자 기준 793 vs 41 TPS). 혼자 한 요청씩 쓰는 맥에서는 키울 batch도 채울 빈 슬롯도 없어 이점이 발현되지 않는다.
Q6. “vllm-mlx로 400+ tok/s 나온다”는 글은 뭔가요? 조건을 봐야 한다. 그 417.9 tok/s는 Qwen3-0.6B-8bit 초소형 모델 + M4 Max 128GB + 단일 스트림 greedy 조건이고, vllm-mlx는 vLLM 공식 org가 아닌 별도 community 프로젝트다. M3 Pro에서 7B를 돌리면 그 근처도 안 나온다.
정리 — 띄울 수는 있고, 학습으로는 값졌다
2026년 5월 기준 M3 Pro 36GB에서 vLLM은 vllm-metal 경로로 Metal GPU까지 써서 7B 4-bit급을 띄울 수 있다. “맥에선 CPU로만 돈다”는 통념은 더 이상 맞지 않는다. 다만 혼자 한 요청씩 쓰는 환경에서는 PagedAttention의 이점이 발현되지 않아 Ollama보다 빠르지도 않다. vLLM이 빛나는 무대는 동시 요청이 쏟아지는 GPU 서버지 내 맥북이 아니다. 그래도 논문 속 구조를 내 GPU 위에서 직접 돌려본 건 다음 단계로 넘어가는 좋은 디딤돌이었다.
다음으로 다룰 것들 — 모두 별도 글로 예정이다.
- 본격 처리량 벤치: 신선한 CUDA GPU(RTX 4090·5090 급)로 vLLM의 batching 한계까지 재본다. 다만 내 홈서버는 RTX 2070(VRAM 8GB)이라 받쳐주기 빠듯해서 시도 여부는 GPU 업그레이드와 같이 고민 중
- Metal vs CUDA 추론 비교: 같은 모델을 두 백엔드에서 (조건 갖춰지면 시도)
- sglang vs vLLM vs Ollama: 언제 무엇을 쓰나, 엔진 결정 트리 (준비 중)
관련 글
- vLLM은 왜 빠른가 — PagedAttention을 OS 페이징으로 이해하기 — 이 글에서 “왜 동시 요청이 많을 때만 빨라지는지” 궁금했다면. PagedAttention과 continuous batching의 원리를 OS 가상 메모리 비유로 푼 개념 글.
- Ollama로 M3 Pro 맥북에 로컬 LLM 띄우기 — 30분 실측 가이드 — 같은 M3 Pro 36GB에서 Ollama로 더 단순하게 띄우는 길. 단일 사용자라면 이쪽이 더 빠를 수 있다.
- Claude API 비용 완벽 가이드 2026 — 토큰 단가·캐싱·배치 할인 — 로컬에서 직접 서빙하는 비용과 클라우드 API 비용을 비교하고 싶을 때 기준점.
참고 자료
- Docker Model Runner with vLLM-Metal on macOS — Docker Blog (2026-02-26) — 경로 3 설치·단일 스트림 벤치(251~279 vs 333~345 tok/s). 단, 블로그가 적은
install-runner명령은 Docker Desktop에서 막힘 — Desktop은desktop enable model-runner --tcp=12434로 우회 - Inference engines — Docker Model Runner Docs — 2026-05 시점 docs는 “macOS vLLM 미지원, llama.cpp 기본” 표기. 블로그(vllm-metal 추가)와 docs(미반영)의 시차로 자동 라우팅 불확정
- Installation — CPU (Apple) — vLLM Docs — 경로 1 CPU backend(experimental)
- vllm-project/vllm-metal — GitHub — 경로 2 공식 플러그인 (v0.2.0)
- vllm-metal supported models — GitHub — MLX 4-bit 지원 모델 범위
- waybarrios/vllm-mlx — GitHub — 비공식 별도 구현 (400+ tok/s 주장의 출처)
- Ollama vs vLLM: a deep dive into performance benchmarking — Red Hat Developer (2025-08-08) — A100 동시성 벤치(793 vs 41 TPS)
CPU backend로 테스트해보니 정말 유용하네요. Ollama와 비교하는 부분도 중요하게 생각하게 되네요.