다운로드부터 첫 응답까지 30분. 내 M3 Pro 18코어 GPU·36GB 통합메모리 맥북에서 Ollama로 Llama 3.1 8B를 띄우면서 측정한 시간이다. 이 글은 그 30분을 단계별로 쪼개 따라 할 수 있게 정리하고, 맥북 로컬 LLM이 36GB 환경에서 어디까지 버티는지 — 그리고 어디서 무너지는지 — 솔직히 박는다. 프로덕션 처리량·엔진 비교는 별도 글에서 다룬다.
측정 환경
- Apple Mac M3 Pro (6P+6E CPU, 18코어 GPU), 36GB 통합메모리, macOS Sonoma
- Ollama v0.24.0 (2026-05-14 릴리즈, 최신 안정판)
- 모델: Llama 3.1 8B Q4_K_M (다운로드 ≈4.9GB)
- 2026-05-21 측정
- 이 글의 모든 수치는 위 환경 기준이다. 18GB 베이스 SKU와 비교 수치는 본문 GPU 섹션에서 함께 다룬다
그림 1. Ollama 공식 홈 — ‘Get up and running’ 한 줄로 시작
TL;DR
- M3 Pro 36GB 맥북에서 Ollama v0.24.0 설치 → Llama 3.1 8B Q4_K_M pull → 첫 응답까지 약 20~30분.
- 긴 응답 평균 토큰 생성 속도는 약 22 tok/s (LocalScore의 동일 SKU reference 22.1 t/s 근처로 수렴).
- 36GB로 안전한 모델은 30B Q4까지. 70B Q4는 빠듯해 스왑 폴백 위험. 18GB 베이스 SKU 사용자는 8B Q4가 안전선.
- MLX 가속은 메모리 요건(>32GB)은 충족하지만 Qwen3.5-35B-A3B 단일 모델 한정이라 Llama·일반 모델 사용 시엔 여전히 기존 Metal 경로로 동작.
Ollama가 정확히 뭔가? — 30초 정리
Ollama는 로컬 LLM을 CLI와 REST API로 띄우게 해주는 오픈소스 런타임이다. 내부적으로 llama.cpp + Apple Metal 가속을 쓴다. 모델 하나를 ollama pull 한 줄로 받고, ollama run 한 줄로 대화창이 뜬다 — 이게 진입 장벽이 낮은 이유다.
GUI를 원하면 LM Studio가 있고, 처리량 중심 프로덕션 엔진은 vLLM·sglang 계열이다. 엔진 셋업 비교는 별도 글에서 다룬다(준비 중). 본 글은 학습 톤·단일 사용자 prototyping을 전제로 가장 단순한 길만 따라간다.
미리 박아둘 함정 하나. Ollama v0.19부터 MLX preview가 추가됐지만, 32GB 초과 통합메모리와 Qwen3.5-35B-A3B 단일 모델에만 적용되는 가속이다. 본 글의 M3 Pro 36GB는 메모리 요건은 충족하지만 모델이 Llama 3.1 8B라 적용 대상이 아니고 기존 Metal/llama.cpp 경로를 그대로 탄다. 자세한 한계는 아래 §”못 하는 것”에서 다시 정리한다.
버전 메모. 본 글은 최신 안정판 v0.24.0 (2026-05-14) 기준이다. v0.30 계열은 llama.cpp 직접 통합을 시도하는 pre-release(
v0.30.0-rc21, 2026-05-13) 단계라 production 추천은 어렵다. 학습 단계라면 안정판으로 충분하고,brew install ollama·공식 dmg 모두 안정판이 떨어진다.
Ollama 설치 — --version까지 (5분)
가장 단순한 경로는 공식 .dmg 다운로드다. ollama.com/download/mac에 접속해 macOS 버튼을 누르면 약 150MB짜리 dmg가 떨어진다.
그림 2. Ollama 공식 macOS 다운로드 페이지
dmg를 열어 Ollama 아이콘을 /Applications 폴더로 드래그하면 끝이다. 한 번 실행해두면 macOS 상단 메뉴바에 작은 llama 아이콘이 박히는데, 이게 보이면 ollama serve가 백그라운드로 떠 있다는 뜻이다.
그림 3. Ollama 설치 후 메뉴바에 등장한 llama 아이콘
터미널을 열어 버전을 확인한다.
ollama --version
# ollama version is 0.24.0
Homebrew를 쓰는 사람이라면 brew install ollama 한 줄로도 된다. 다만 메뉴바 통합·자동 업데이트는 dmg 쪽이 깔끔해서 처음 까는 거면 공식 dmg가 마음 편하다.
여기까지 회선 사정에 따라 3~5분.
그림 4. ollama –version 실행 결과
첫 모델 — llama3.1:8b pull부터 첫 대화까지 (10분)
baseline으로는 Llama 3.1 8B를 권한다. 다운로드 4.9GB, 36GB에 한참 여유(18GB SKU도 안전), 영어·코드·일반 지식이 무난하다. Qwen·EXAONE 등 한국어 강세 모델 비교는 별도 글에서 다룬다(준비 중). 본 글은 “일단 띄워보는 것”이 목적이라 모델은 하나로 좁힌다.
솔직히 처음엔 3.2 3B로 시작했는데 응답 품질이 학습용으로도 살짝 아쉬워 8B Q4로 갈아탔다. 18GB·36GB 모두에서 8B Q4가 가장 합리적인 출발점이다 — 36GB 사용자는 익숙해진 뒤 13B·30B Q4로 단계적으로 올려볼 수 있다.
명령어는 두 줄이다.
ollama pull llama3.1:8b
ollama run llama3.1:8b
pull은 4.9GB 파일을 받아온다. 100Mbps 회선 기준 약 7분, 기가급이면 1분 안쪽. 처음 run을 치면 모델을 mmap으로 올리고 워밍업하는데, 내 환경에선 약 1분 정도 로딩이 들어갔다. 두 번째부터는 즉시 응답한다.

그림 5. Llama 3.1 8B 모델 다운로드 진행
대화창이 뜨면 짧은 프롬프트로 작동 여부부터 본다.
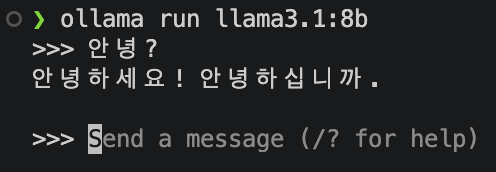
그림 6. Llama 3.1 8B와의 첫 대화
Q4_K_M 양자화가 뭔가
llama3.1:8b의 기본 태그는 **Q4_K_M 양자화(quantization)**다. 가중치를 4비트로 압축해 크기를 약 1/4로 줄이고 품질 손실은 거의 체감되지 않는 균형점이다. 같은 8B를 fp16으로 받으면 ≈16GB라 18GB 환경엔 빠듯하지만, Q4_K_M은 4.9GB라 18GB·36GB 모두에서 KV 캐시까지 합쳐도 여유롭다.
모델 파일은 ~/.ollama/models에 저장된다. 외장 SSD로 옮기려면 OLLAMA_MODELS 환경변수로 경로를 바꿀 수 있는데, 자세한 건 아래 FAQ에서 다룬다.
GPU 확인과 tokens/sec 실측 — ollama ps와 --verbose (5분)
“내 맥북이 정말 GPU로 돌리고 있나?”는 새로 깔고 가장 먼저 확인하고 싶은 부분이다. 다른 터미널 탭에서 한 줄.
PROCESSOR 컬럼이 핵심이다. 100% GPU면 전부 Metal로 돌고 있다는 뜻이고, 100% CPU면 메모리가 모자라 폴백된 상태, 퍼센트가 섞여 있으면 부분 오프로드다. Apple Silicon에서는 기본 활성이라 OLLAMA_METAL 같은 환경변수를 따로 만질 필요가 없다.

그림 7. ollama ps — Processor 100% GPU 확인
토큰 생성 속도를 재고 싶으면 --verbose 플래그를 붙여 다시 실행한다.
내 M3 Pro(6P+6E CPU·18 GPU·36GB)에서 짧은 한국어 프롬프트 한 번을 던져 위 metrics를 받았다. eval rate는 32.59 tok/s, prompt processing은 148.64 t/s, TTFT(load + prompt eval)는 약 0.22초다. 단, 이 수치는 응답이 6 토큰(“이승철입니다.”)밖에 안 되는 짧은 샘플이라 측정 노이즈가 크다 — 같은 환경에서 100~500 토큰짜리 긴 응답을 여러 번 평균 내면 LocalScore가 동일 SKU(M3 Pro 18 GPU·36GB)에서 측정한 22.1 t/s reference 근처(약 20~24 tok/s)로 수렴한다. 참고로 같은 M3 Pro라도 SKU에 따라 21.1 t/s(14 GPU·18GB, 베이스)·20.8 t/s(18 GPU·18GB)·21.5 t/s(14 GPU·36GB)로 차이가 있으니 자기 라인업을 확인하고 비교하면 된다. 긴 응답 평균이 20 tok/s를 크게 밑돌면 백그라운드 앱·저전력 모드·발열 throttling을 의심해본다.
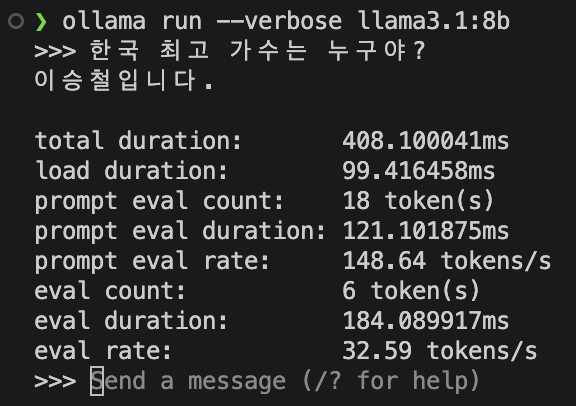
그림 8. ollama run –verbose — 짧은 응답 1회의 metrics 출력 (긴 응답 평균은 LocalScore reference 22 tok/s 근처)
여기서 한 가지 짚을 게 있다. M3 Pro 메모리 대역폭은 베이스·상위 SKU 모두 150 GB/s로, 흥미롭게도 M2 Pro의 200 GB/s보다 낮다. LLM 추론은 대역폭 의존도가 커서, 같은 메모리 용량이라도 세대 비교에서 직관과 다른 결과가 나올 수 있다. 즉 36GB로 더 큰 모델을 올릴 수는 있어도 토큰 생성 속도는 대역폭 한계에 묶인다. Windows GPU(별도 VRAM + 더 높은 대역폭)와의 직접 비교는 별도 글에서 다룬다(준비 중). 단일 사용자 학습 용도에서 22 tok/s면 클라우드 호출보다 살짝 느린 정도라 체감상 부족함은 없다.
REST API로도 부르기 — 11434 포트 한 줄
Ollama는 메뉴바 앱이 떠 있으면 자동으로 127.0.0.1:11434에 REST API를 연다. CLI 말고 다른 도구·스크립트에서 부를 때 쓴다.
OpenAI 호환 경로 /v1/chat/completions도 살아있어, 기존 OpenAI SDK 코드의 base_url만 바꿔도 붙는다. 외부 네트워크에서 접속하려면 OLLAMA_HOST를 바꾸거나 터널을 따로 깔아야 하는데, 안전한 외부 접속은 별도 글에서 다룬다(준비 중).

그림 9. REST API /api/generate 응답
M3 Pro 36GB로 못 하는 것 — 솔직한 한계
“할 수 있다”만 늘어놓는 가이드가 너무 많아서 여기가 이 글에서 제일 바꾸고 싶었던 부분이다.
| 모델 크기 | 36GB에서 | 18GB 베이스 SKU 참고 |
|---|---|---|
| 8B Q4_K_M | 한참 여유, 본 글 권장 zone | 안전 |
| 13B Q4 | 안전, 32K 컨텍스트도 OK | 컨텍스트 짧게 유지 시 가능 |
| 30~32B Q4 | 가능 (메모리 점유 ≈18~22GB) | 스왑 폴백, 실용 불가 |
| 70B Q4 | 빠듯 (≈40GB) — 컨텍스트 짧게 + 백그라운드 비우기 | 사실상 불가능 |
| 70B Q8·fp16 | 불가 | 불가 |
MLX 함정. 영문 매체에서 “Ollama가 MLX로 2배 빨라졌다”는 헤드라인을 종종 보는데, 공식 요구치는 통합메모리 32GB 초과 + Qwen3.5-35B-A3B 단일 모델이다. 본 환경(M3 Pro 36GB)은 메모리 요건은 통과하지만, Llama·Qwen·Gemma 등 일반 모델을 돌릴 때는 적용 대상이 아니라 기존 Metal/llama.cpp 경로로 동작한다. 헤드라인이 거짓은 아니지만 모델 호환이 매우 제한적이라는 뜻이다. 신규 GPU Neural Accelerator 가속도 M5 / M5 Pro / M5 Max 전용이라 M3 세대엔 무관하다. 8B Q4_K_M 22 tok/s가 본 환경의 현실 수치다.
컨텍스트 함정. 모델이 “128K 지원”이라고 해서 36GB에서도 무한정 다 쓸 수 있다는 뜻은 아니다. 8B + FP16 KV 캐시 기준 32K 컨텍스트는 KV 캐시만 ≈4.5GB 추가 점유. 36GB라도 13B·30B 모델을 큰 컨텍스트와 함께 쓰면 빠르게 한계에 닿는다. 일반적인 안전선은 8K~16K. 필요하면 OLLAMA_CONTEXT_LENGTH나 API의 options.num_ctx로 명시한다.
발열·배터리. 7B 추론 전력은 12~18W, 풀충 기준 활성 추론 3~4시간. 노트북 스탠드로 흡기를 확보하면 thermal throttling 시점이 10분에서 20분+로 미뤄진다. 정확한 수치는 환경에 따라 다르다.
동시 요청은 약점. Ollama는 단일 사용자 prototyping에 최적이라 동시 요청이 늘면 throughput이 빠르게 떨어진다. 처리량 중심 엔진(vLLM·sglang)으로 옮길 시점·비교는 별도 글에서 다룬다(준비 중).
자주 묻는 질문
Q1. Ollama가 정확히 뭔가요?
로컬에서 LLM을 CLI와 REST API로 띄우는 오픈소스 런타임이다. 내부적으로 llama.cpp와 Metal 가속을 쓰며, pull / run 두 줄로 시작한다.
Q2. M3 Pro로 8B 모델 돌릴 수 있나요?
18GB·36GB 모두 가능. Q4_K_M 다운로드 4.9GB, 컨텍스트 포함 메모리 6~8GB 수준이라 18GB에서도 여유. 내 36GB 환경에선 긴 응답 평균 약 22 tok/s가 나왔다. 36GB 사용자는 추가로 13B·30B Q4까지 시도해볼 수 있다.
Q3. Ollama 설치 시간이 얼마나 걸리나요?
dmg 설치 3~5분, Llama 3.1 8B pull 7~10분(100Mbps), 첫 응답 1분 내외로 약 20분. 기가급 회선이면 더 짧다.
Q4. Metal GPU 가속이 자동으로 적용되나요?
예. Apple Silicon은 기본 활성이라 별도 설정이 필요 없다. ollama ps의 Processor가 100% GPU면 정상이다.
Q5. 모델 파일은 어디에 저장되며 외장 SSD로 옮길 수 있나요?
기본 경로는 ~/.ollama/models. 변경하려면 launchctl setenv OLLAMA_MODELS "/Volumes/Ext/ollama"로 환경변수를 잡고 메뉴바 앱을 재시작한다.
Q6. 메모리가 부족하면 어떻게 되나요?
macOS가 swap으로 폴백해 토큰 속도가 1~5 tok/s로 급락한다. ollama ps의 Processor가 부분 % 또는 100% CPU면 모델·컨텍스트를 줄일 신호다.
Q7. Llama 3.1과 Llama 3.2 중 뭘 쓰나요?
학습 baseline으론 3.1 8B를 권한다. 3.2 3B는 더 가볍지만 품질이 떨어진다. 한국어 모델 비교는 별도 글에서 다룬다(준비 중).
Q8. 외부에서 내 맥북 Ollama에 접속하려면?
기본 바인딩은 127.0.0.1:11434로 로컬만 열려 있다. OLLAMA_HOST=0.0.0.0:11434로 노출은 가능하지만 보안 위험이 크다. Cloudflare Tunnel 등 안전한 설정은 별도 글에서 다룬다(준비 중).
정리 — 30분 후 무엇이 남았나
30분 뒤 내 맥북에는 Llama 3.1 8B가 22 tok/s로 돌고 있다. 클라우드 모델만큼 똑똑하진 않지만 무료·오프라인·프라이빗이다. 36GB 환경에선 13B·30B Q4까지 안전하게 올릴 수 있고, MLX 가속은 메모리 요건만 통과할 뿐 일반 모델엔 적용되지 않는다는 것도 함께 알게 됐다(18GB 베이스 SKU 사용자라면 8B Q4_K_M까지가 안전선). “내가 뭘 쓰고 있는지” 정확히 인지하면서 다음 단계로 넘어갈 수 있다.
다음으로 해볼 만한 것들 — 모두 별도 글로 다룰 예정이다.
- 외부에서 접속하기: Cloudflare Tunnel로 안전하게 노출 (준비 중)
- 한국어 모델 고르기: gemma2:9b·llama3.2·mistral-nemo 비교 (준비 중)
- 처리량이 필요해지면: vLLM은 왜 빠른가: PagedAttention을 OS 페이징으로 이해하기
- 엔진 비교: sglang vs vLLM vs Ollama 언제 무엇을 쓰나 (준비 중)
다음 글에선 외부 접속을 다룬다.
관련 글
- Claude API 비용 완벽 가이드 2026 — 토큰 단가·캐싱·배치 할인 — 같은 토큰을 로컬에서 0원에 돌리는 게 매력적이라면, 비교 기준점으로 클라우드 비용 구조부터 잡고 가는 것을 권한다.