“claude 코딩으로 진짜 2배 빨라지나”라는 질문을 자주 받는다. 솔직히 답하면 작업 종류에 따라 폭이 크다. GitHub와 Microsoft Research가 함께 한 Copilot 연구에서는 HTTP 서버 구현 한 작업이 55% 빠르게 끝났다(1시간 11분 vs 2시간 41분)는 결과가 보고됐다 GitHub Blog. McKinsey 조사에서는 복잡 작업을 25-30% 더 많이 시간 내 완료한다고 보고됐다 McKinsey: Unleashing. 같은 회사의 별도 보고서에서는 AI를 쓰는 팀이 평균 주 6시간을 절감한다고 측정됐다 McKinsey: Unlocking. 단, 같은 보고서가 단서를 단다. 고난도 작업의 시간 절감은 10% 미만이고, 1년 미만 주니어는 7-10% 느려질 때도 있다.
그래서 “2배”는 후크고, 본 글은 2026년 4월 기준 매일 쓰는 5가지 활용 패턴을 정리한다. 코드 리뷰·디버깅·새 기능 초안·테스트·한국어 주석 및 커밋 — 한국 개발자가 코딩에 가장 많이 쓰는 LLM이 Claude(42%)라는 조사 결과도 있고 바이라인네트워크, 본인이 클로드 코딩에 들이는 시간 대부분도 이 다섯 갈래로 갈린다. 이미 깔린 사용자 전제니, 처음이라면 Claude Code 설치부터 첫 명령까지을 먼저 보고 오면 좋다.
TL;DR. Claude로 매일 쓰는 활용 패턴 5가지(코드 리뷰·디버깅·새 기능 초안·테스트·한국어 주석/커밋)와 프롬프트 템플릿을 정리했다. “2배”는 후크일 뿐, 실제 정량은 Copilot 55%·McKinsey 25-30%·주 6시간으로 폭이 크다. 단순 자동화는 분명히 빨라졌고, 고난도 설계는 거의 그대로다.
패턴 A — Claude 코드 리뷰와 리팩터링
가장 빈도 높게 쓰는 패턴이다. PR diff 또는 파일 한 덩이를 던지고 시니어 동료 톤으로 리뷰를 받는다. Anthropic 공식 best practice가 권장하는 핵심은 Writer/Reviewer 분리 — “fresh context improves code review since Claude won’t be biased toward code it just wrote” Best Practices.
작성한 세션 안에서 같은 모델에 리뷰를 시키면 본인이 짠 코드를 옹호한다. /clear 한 번 치고 새 세션에서 리뷰만 시키는 편이 낫다.
CodeRabbit 자체 평가에서 Opus 4.7는 알려진 버그 100건 중 68건을 잡았고(pass rate 68/100), 종합 점수는 74/100으로 이전 베이스라인 60점에서 올라갔다고 보고된다. actionable 코멘트 비율도 54%에서 64%로 상승했다 CodeRabbit.
작성 세션과 리뷰 세션을 분리하라는 게 핵심이지, 모델 자체로 모든 PR 크기에서 똑같이 강한 건 아니다 — 작은 변경은 사람 눈으로 빠르게 보고 큰 변경에 Claude를 붙이는 편이 컨텍스트 비용 측면에서 효율이 좋다.
역할: 시니어 동료 리뷰어. 톤은 단호하고 친절하게.
대상: @src/api/orders.ts (PR diff는 아래 첨부)
관점: 1) 정확성 2) 엣지 케이스 3) 보안 4) 우리 컨벤션과의 일관성
형식: 발견한 이슈마다 (a) 줄 번호 (b) 왜 문제인지 (c) 수정 코드 (d) 그 이유.
중요: 사소한 nit은 생략. high/medium만.
여기서 자주 빠뜨리는 게 우리 컨벤션과의 일관성 한 줄과 nit 컷오프다. 둘을 빼면 일반론적인 리뷰가 돌아오고, 본문이 길어진다.
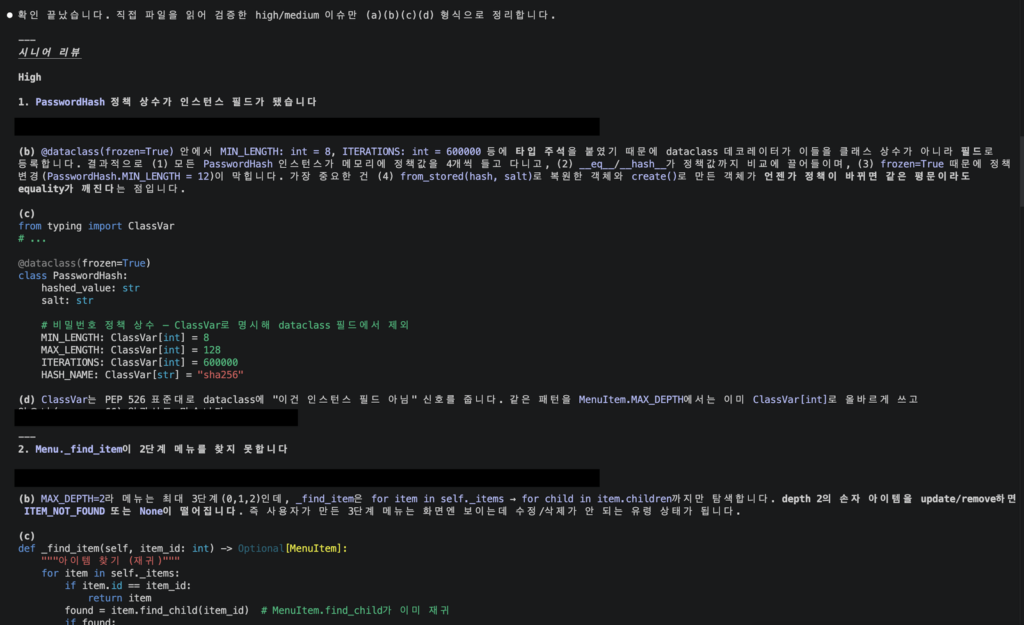
그림 1. Claude 코드 리뷰 응답 예시
패턴 B — Claude 디버깅: 가설부터 받는다
에러가 생기면 메시지·재현 흐름·의심 위치·”고쳤다는 것의 정의”를 함께 던진다. 공식 권장은 단호하다. “Address root causes, not symptoms” — 증상을 덮지 말고 원인을 짚으라는 한 줄이다 Best Practices.
체감 차이가 가장 컸던 변형은 failing test부터 작성시키는 흐름이다. 공식 권장 프롬프트도 “write a failing test that reproduces the issue, then fix it” 형태를 쓴다. 검증 수단 없이 그럴듯한 코드만 받으면 엣지케이스가 누락된다 — 공식 가이드의 표현 그대로 “If you can’t verify it, don’t ship it”.
증상: [에러 메시지/스택 트레이스 그대로 붙여넣기]
재현: [클릭 흐름 또는 cURL 한 줄]
의심 위치: src/auth/session.ts 의 refresh 분기
요청: 1) 가장 가능성 높은 가설 3개 2) 각 가설을 빠르게 확인할 수 있는 점검 명령
3) 가설이 맞으면 어떤 테스트가 실패해야 하는지 — 테스트부터 작성, 그다음 수정.
가설 3개를 강제하는 이유는 한 번에 정답으로 직진시키지 않기 위해서다. 두 번째·세 번째 가설이 진짜 원인인 경우가 잦다.
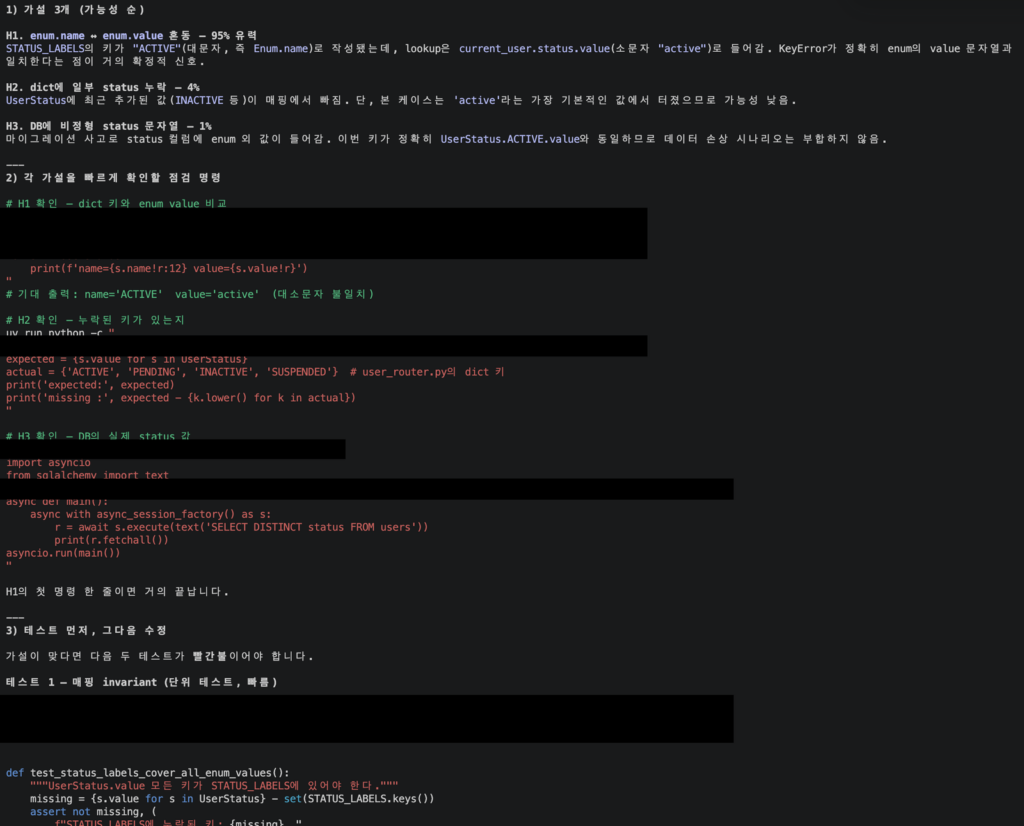
그림 2. Claude 디버깅 응답 예시
패턴 C — 새 기능 초안: 스펙 → 함수 → 테스트
큰 기능을 한 번에 시키면 거의 어긋난다. Anthropic 공식은 4단계 워크플로우를 권한다. Explore → Plan → Implement → Commit. Plan Mode로 파일 구조를 파악한 뒤 Normal Mode로 전환하는 흐름이다 Best Practices.
큰 기능에는 “Let Claude interview you” — AskUserQuestion 도구로 역질문을 받게 하고 SPEC.md에 저장한 다음, 새 세션에서 그 SPEC을 보고 구현시킨다.
Simon Willison이 정리한 패턴도 결이 같다. 단순 버전부터 만들고, 동작을 확인한 뒤, 정교화한다 How I use LLMs.
한 번에 완성품을 만들지 않는다는 원칙이다.
목표: 사용자가 마감일 지난 할 일을 요약 카드로 보는 기능.
제약: React + 우리 디자인 시스템(@components/Card 사용), 외부 라이브러리 추가 금지.
순서: 1) 인터페이스/타입부터 제안 2) 빈 함수 시그니처 3) 실패 케이스 테스트 1개
4) 그 테스트를 통과하는 최소 구현. 단계마다 멈추고 내 확인을 받아.
웹 채팅이라면 결과를 Claude Artifacts로 미리 돌려볼 수 있어, 타입·시그니처·테스트 1개의 결합이 즉석에서 검증된다. *”바이브 코딩(vibe coding)”*이라는 말이 유행하지만 — Karpathy가 2025년 2월 X 포스트에서 *”fully give in to the vibes”*로 명명했다 Wikipedia — 이 패턴에서는 단계마다 멈추고 사람이 확인하는 편이 안전하다.
패턴 D — 테스트 작성과 문서화
기존 함수의 입출력을 표로 뽑고 그걸 그대로 테스트 케이스로 옮기는 작업은 사람보다 빠르다. 공식 best practice의 권장 톤도 구체적이다. “write a test for foo.py covering the edge case where the user is logged out. avoid mocks.” 시나리오와 모킹 정책까지 같이 넣으라는 뜻이다.
Anthropic 사내 팀이 공유한 PDF에는 design doc → janky code → refactor → give up on tests 패턴을 pseudocode → guide TDD → check in periodically로 바꾼 사례가 있다 How Anthropic teams use Claude Code. 리팩터 전 characterization tests로 현재 동작을 잠가두라는 조언도 같이 나온다.
대상: @utils/parseDate.ts (현재 60줄)
요청: 1) 이 함수가 다루는 입력 타입을 추출 (정상/엣지/오동작 추정)
2) 그 입력별 기대 출력을 표로 정리
3) Vitest 테스트 케이스로 옮겨. 모킹은 쓰지 말고 실제 입출력만.
4) 실패 케이스를 발견하면 코드 수정 전에 일단 모두 보여줘.
마지막 줄이 핵심이다. 실패 케이스를 발견했을 때 코드를 먼저 고쳐버리면, 어떤 동작이 의도였는지 사람이 잃는다.
패턴 E — 한국어 주석과 커밋 메시지
한국 개발자에게만 통하는 패턴이다. Anthropic 공식 한국어 docs는 존재하지만 code.claude.com/docs/ko/overview, 주석·커밋 메시지 컨벤션 가이드는 따로 없다. 그래서 본인은 CLAUDE.md에 5-7줄짜리 규칙을 박아두는 식으로 자리를 잡았다 — CLAUDE.md는 매 세션 자동 로드되니 한 번만 박으면 된다.
규칙(한 번만 지정):
- 주석은 한국어, 존댓말 X, 명령형/설명형으로 통일
- 변수명은 영어 유지, 도메인 용어는 영어 그대로(예: idempotency, payload)
- 1줄 주석은 // 한국어, 다중 줄은 /** ... */ 영어 한 줄 + 한국어 본문
- 커밋 메시지: <type>: <한국어 한 줄 요약>(50자 이내) + 빈 줄 + 한국어 본문
이 5줄을 박아두니 체감 8할 정도는 일관성이 유지된다. 다만 최근 몇 주 쓰면서 멈칫한 적이 한 번 있는데, 긴 세션 후반에 한국어 주석 사이로 일본어 단어가 한두 개 섞여 들어왔다. GitHub 이슈 #24941로도 보고된 사례라 본인 환경 문제는 아니었다 Issue #24941. /clear로 세션을 끊고 다시 시작하면 정상으로 돌아온다.
CLI에 한국어를 직접 입력할 때 IME composition이 깨지는 문제도 있다 Issue #4866. 본인은 결국 에디터에서 한국어 프롬프트를 작성한 다음 붙여넣는 습관이 자리 잡았다. 작은 우회지만 성가신 편이다.
흔한 실수와 헤맴
공식 best practice와 커뮤니티 이슈를 보면 비슷한 함정이 반복된다.
- kitchen sink session — 한 세션에 무관한 작업을 섞으면 컨텍스트가 오염된다.
/clear로 리셋하라는 게 공식 권장이다. - 2번 정정해도 안 고쳐지면 같은 세션에서 더 다듬지 말고
/clear후 더 구체적인 프롬프트로 재시작. - 검증 없이 ship 금지 — 테스트·실행 결과·스크린샷 중 하나는 함께 받아라. If you can’t verify it, don’t ship it.
- max_tokens로 잘림 — Claude Code는 32K 캡이 있고, 긴 마이그레이션 코드는 중간에 끊긴다 Issue #24055. 분할 요청이 안전하다.
- 다중 파일 리팩터에서 reintroduce — 이전에 손댄 파일을 잊고 같은 코드를 다시 만들어 넣는다 DoltHub Gotchas. 작은 커밋 단위로 끊어 가는 편이 낫다.
직접 헤맨 사례 하나. 지난 분기에 자동화 스크립트 두 개를 한 세션에 던졌다가, 두 번째 결과가 첫 번째를 일부 덮어쓴 적이 있다. Sonnet 4.5 시점이었고, 컨텍스트가 길어지면서 첫 스크립트 사양을 잊어버린 모양이었다. 이후로는 작업당 새 세션을 강제한다 — 답답해 보여도 결과는 더 깨끗하다.
모델·환경 선택은 어떻게 할까
기본은 Sonnet 4.6이다. 패턴 A·B·D 대부분에 충분하고, 빠르고, 비용도 적정선이다. 멀티 파일 리팩터·복잡한 디버깅·긴 호흡 작업에 가서야 Opus 4.7로 에스컬레이션한다 — SWE-bench Verified에서 87.6%로 보고된다 TokenMix. 단발 질문은 Pro 웹 채팅, 파일 자율 편집·테스트 실행은 Claude Code CLI다. 모델별 코딩 차이의 더 자세한 비교는 Claude Opus vs Sonnet vs Haiku 차이에 정리해뒀고, API로 직접 호출할 때 단가는 Claude API 비용 가이드에 별도로 두었다. Cursor와의 IDE 비교는 별도로 정리 중(준비 중).
그림 3. Claude Code Best Practices 페이지
자주 묻는 질문
Q1. Claude로 어떤 코딩 작업을 잘하나요?
코드 리뷰·디버깅·새 기능 초안·테스트 자동화·한국어 주석/커밋 같은 패턴화된 작업이다. 시스템 설계·아키텍처 결정 같은 큰 그림은 사람이 가이드해야 한다.
Q2. Claude로 디버깅이 되나요?
된다. 단 에러 메시지·재현 흐름·의심 위치를 함께 줘야 한다. 위 패턴 B 템플릿처럼 가설 3개부터 받고 → 점검 명령 → failing test → 수정 순서를 강제하면 그럴듯한 가짜 답을 거를 수 있다.
Q3. 한국어 주석·커밋 메시지를 잘 쓰나요?
한국 개발자가 코딩에 가장 많이 쓰는 LLM이 Claude(42%)라는 조사가 있을 만큼 한국어 출력은 자연스럽다. CLAUDE.md에 5줄짜리 컨벤션 규칙을 박아두면 일관성 체감 8할이고, 긴 세션 후반에는 일본어 단어가 섞여 들어오는 사례가 있다.
Q4. Pro 구독으로 코딩 충분한가요?
패턴 A·B·D는 Pro 웹 채팅으로 대부분 가능하다. 멀티 파일 자율 편집·테스트 실행 같은 작업은 Claude Code CLI 쪽이 결이 맞다. 모델 차이는 Claude Opus vs Sonnet vs Haiku 참고.
Q5. Cursor·Copilot보다 나은 점은?
본 글은 Claude 단독 활용 패턴이라 깊은 비교는 다루지 않는다. 한국 개발자 점유 1위(42%)와 긴 호흡 작업 강점이 자주 거론되는 포인트다. 모델 단위 비교는 Claude vs GPT vs Gemini에서, Cursor와의 IDE 비교는 준비 중이다.
Q6. Claude 코드 리뷰 어떻게 시키나요?
패턴 A 템플릿을 그대로 복사해 쓰고, 작성 세션과 리뷰 세션을 분리한다(/clear). 컨벤션 한 줄과 nit 컷오프를 빼면 일반론적 리뷰가 돌아온다.
Q7. AI 코딩으로 진짜 생산성이 늘어나나요?
체감으로는 단순 자동화·테스트·리뷰에서 시간이 분명히 줄었다. 정량으로는 Copilot 연구 55%·McKinsey 25-30%·주 6시간 같은 수치가 보고됐지만, 작업 종류·연차에 따라 폭이 크고 주니어가 더 느려진 사례도 있다. “2배 빨라진다”고 단정할 근거는 어느 1차 자료에도 없다.
다음 걸음
본인 워크플로우에 패턴 다섯 중 하나를 박아 넣는 것부터 시작하면 된다. 코드 리뷰가 가장 빠르게 효과가 보이는 편이다. 아직 Claude Code를 깔지 않았다면 Claude Code 설치부터 첫 명령까지으로, 이미 깔았다면 모델 선택은 Opus vs Sonnet vs Haiku에서 정리해두면 된다.
관련 글
- Claude Code 설치부터 첫 명령까지 (2026) — 처음이라면 설치부터
- Claude Opus vs Sonnet vs Haiku 차이 완벽 정리 — 코딩에 어느 모델을 쓸지
- Claude Artifacts 사용법 완벽 정리 — 채팅 옆 코드 패널 활용
- Claude API 비용 완벽 가이드 2026 — 자동화·일괄 처리 비용 시뮬레이션
- Claude vs GPT vs Gemini 2026 — 다른 챗봇과 비교
- Cursor vs Claude Code (추후 발행) — IDE·코딩 도구 비교