지난 2주간 같은 프로젝트 안에서 Claude Opus 4.7·Sonnet 4.6·Haiku 4.5를 번갈아 써봤다. 결론부터 말하면 “어떤 게 제일 좋은가”보다 “언제 뭘 켜느냐”가 훨씬 중요했다. 이 글은 2026-04 기준 최신 라인업을 놓고 Claude Opus vs Sonnet vs Haiku 차이를 스펙·가격·결정 트리 세 축으로 정리한다. claude 모델 비교를 넘어 “Pro 구독자면 Opus만 쓰면 되는가” 같은 실전 오해까지 같이 본다. 외부 모델 비교(Claude vs GPT vs Gemini)는 별도 글에서 다룬다.
TL;DR
- 코딩·긴 문서·복잡 추론 → Opus 4.7
- 일상 작업·챗봇·콘텐츠 작성 → Sonnet 4.6 (기본값)
- 대량 처리·빠른 응답·비용 민감 → Haiku 4.5
2026년 4월 Claude 라인업 한눈에
세 모델은 가격이 5:3:1로 계층화돼 있고, 컨텍스트·추론 모드·속도가 단계적으로 다르다. Claude 3모델 비교표로 claude 4.7 4.6 4.5 차이를 한 번에 보자.
| 항목 | Opus 4.7 | Sonnet 4.6 | Haiku 4.5 |
|---|---|---|---|
| 출시일 | 2026-04-16 | 2026-02-17 | 2025-10-15 |
| 컨텍스트 | 1M 토큰 | 1M 토큰 | 200k 토큰 |
| 최대 출력 | 128k | 64k | 64k |
| Thinking | Adaptive 전용 | Extended + Adaptive | Extended |
| 입력 가격 | $5 / MTok | $3 / MTok | $1 / MTok |
| 출력 가격 | $25 / MTok | $15 / MTok | $5 / MTok |
| 공식 포지셔닝 | 복잡한 추론·에이전트 코딩 최강 | 속도와 지능의 최고 조합 | 최첨단에 가까운 빠른 모델 |
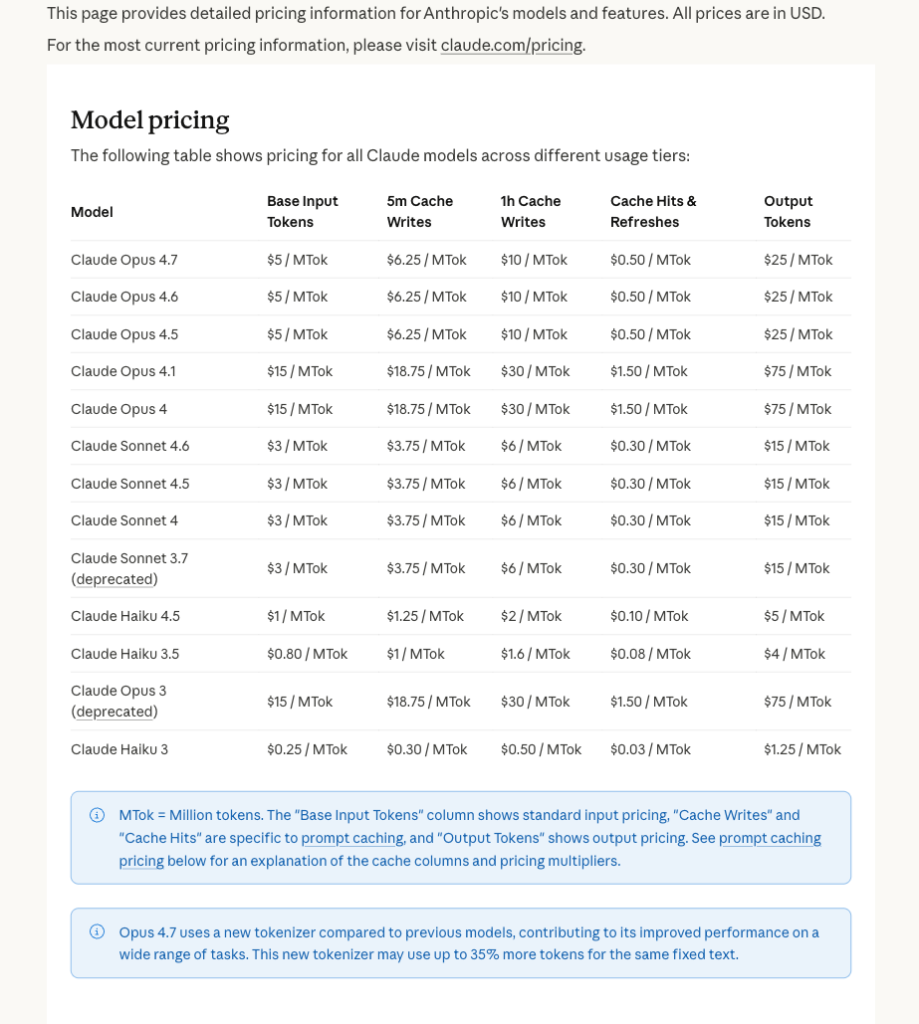
그림 1. Anthropic 공식 Claude API 가격 페이지
Opus 4.7은 새 토크나이저를 쓴다. 같은 텍스트가 이전보다 최대 ~35% 더 많은 토큰을 소모할 수 있다는 공식 고지가 있다. 한국어처럼 토큰 효율이 원래 낮은 언어는 체감 비용이 한 단계 더 올라간다. 한 가지 타이밍 신호 — 바로 오늘(2026-04-19) Claude Haiku 3가 retirement된다. 이미 Haiku 4.5로 넘어왔거나 넘어올 계획이라면 마이그레이션을 더 미룰 이유는 없다.
Claude Opus 4.7 — 언제 이걸 선택해야 하나
Opus 4.7은 코딩·에이전트·긴 문서에서 최강이고, 그 외엔 과잉 투자다. Anthropic 공식 시스템 카드 기준 SWE-bench Verified는 Opus 4.6의 80.8%에서 **87.6%**로 올랐고, Sonnet 4.6(79.6%)보다 약 8pp 앞선다. claude opus 1M 컨텍스트는 표준 가격 그대로 제공된다 — 공식 문구로 “900k 토큰 요청도 9k 요청과 동일한 per-token 요율”.
Claude Opus vs Sonnet 선택에서 Opus를 켤 가치가 있는 상황은 좁다.
- 수만 줄 이상 대규모 리팩터링, 장시간 자율 에이전트
- 수십만 토큰 분량 문서·코드 분석
- GPQA 수준 과학 추론
반대로 한두 문단 답변, 일상 대화, 창작 초안, 단순 요약은 돈 낭비다. 필자가 2주 써본 체감으론 긴 리팩터링에서는 Sonnet 4.6보다 확실히 덜 실수했지만, 답 길이가 짧고 기계적이 됐다는 인상이 있었다. Anthropic도 공식 문서에서 “더 직접적이고 덜 아첨하는 톤, Opus 4.6 대비 이모지 감소”라고 못박는다. 이 부분은 아래 체감 포인트에서 다시 본다.
Opus 4.7은 temperature/top_p/top_k 비기본값과 수동 budget_tokens 지정이 불가하니 마이그레이션 시 주의하자.
Claude Sonnet 4.6 — 대부분의 작업에서 합리적인 이유
Sonnet 4.6은 Free·Pro의 기본 모델이고, claude sonnet 코딩 품질도 Opus와 거의 붙는다. SWE-bench Verified 79.6% — Opus 4.6(80.8%)과 단 1.2pp 차다. Anthropic 자체 선호도 테스트에선 개발자 **70%**가 Sonnet 4.5보다 4.6을, **59%**가 Opus 4.5보다 Sonnet 4.6을 선호했다. 공식 블로그 표현으로 “이전에는 Opus급이 필요했던 수준의 성능”이다.
흔한 오해 — “코딩이면 Opus가 무조건 낫다” Opus 4.7 세대에서 격차가 +8pp로 벌어진 건 맞지만, Sonnet 4.6도 최상위권이고 가격은 Opus의 3/5이며, Opus 4.7의 새 토크나이저까지 감안하면 실질 비용 차이는 더 벌어진다. 단순 함수 수정·리뷰·설명엔 Sonnet이 합리적이다.
Sonnet 4.6은 1M 컨텍스트를 표준 가격으로 제공하고 extended·adaptive thinking 모두 지원한다. Claude.ai 로그인하면 거의 Sonnet이 떠 있다. 모바일에서도 동일하게 기본값이 Sonnet이라 Claude 모바일 앱에서 모델을 전환하는 법은 따로 한 번 짚어볼 가치가 있다. 저는 이걸 이렇게 씁니다 — 기본은 Sonnet, 답이 흔들릴 때만 Opus로 끌어올린다. 기본 작업 모델로 품질과 비용의 균형이 가장 실용적이다.
그림 2. Claude.ai 모델 선택 드롭다운
Claude Haiku 4.5 — 빠르고 저렴, 그런데 품질은?
Haiku 4.5는 Sonnet 4 수준의 코딩 품질을 1/3 가격·2배+ 속도로 제공한다. claude haiku 언제 쓰나의 답은 대체로 긍정적이다. 공식 SWE-bench Verified 73.3%, Sonnet 4.5(77.2%) 대비 3.9pp 차다. Anthropic은 “Sonnet 4와 유사한 수준의 코딩 성능”이라 공식 표현했고, Tome CEO는 “Sonnet 4.5 대비 최대 4-5배 빠름”이라 전했다. claude haiku 속도 체감은 Haiku 계열 최초로 extended thinking·computer use까지 지원한다는 점과 합쳐진다. “저급 모델” 편견을 깨는 지점이다.
주의할 게 있다. Haiku 4.5 ≈ Sonnet 4는 맞지만 ≠ Sonnet 4.6이다. 현 세대 Sonnet과는 엄연히 격차가 있고, 컨텍스트 200k 제한으로 긴 문서 한 번에 처리엔 부적합하다.
claude haiku 품질 괜찮나는 용도별로 갈린다. 적합한 쪽은 대량 분류·요약 파이프라인(Batch API 50% 할인 시 입력 $0.50/MTok), 실시간 챗봇, 간단한 도구 호출 에이전트, 2단 구조의 초안 생성용이다. 반대로 법률·의료처럼 한 번의 실수 비용이 크거나 창작·긴 분석엔 Sonnet·Opus가 맞다.
상황별 Claude 모델 선택 결정 트리
claude 모델 선택 가이드는 작업 성격 4축으로 거의 자동 결정된다. claude 어떤 모델 써야 하나는 이 플로우를 순서대로 따라가면 된다.
Q1. 한 번에 300k 토큰 이상 문서·코드를 다루는가?
- YES → Opus 4.7 또는 Sonnet 4.6 (Haiku는 200k 제한)
- 긴 호흡 추론·에이전트 자율성 → Opus 4.7
- 요약·Q&A·단순 추출 → Sonnet 4.6
- NO → Q2
Q2. 응답 지연이 1-2초 내 필수인가?
- YES → Haiku 4.5 (복잡한 건만 Sonnet으로 에스컬레이션)
- NO → Q3
Q3. 복잡한 리팩터링·과학 추론·장시간 에이전트인가?
- YES → Opus 4.7
- NO → Sonnet 4.6 (기본값)
Q4. 비용 민감 대량 처리인가?
- YES → Haiku 4.5 + Batch API (50% 할인)
- NO → Q3 결과 유지
상황별 추천을 한 줄로 하면 — 의심스러우면 Sonnet 4.6으로 시작해서 답이 흔들릴 때만 Opus로 에스컬레이션하는 게 기본기다. 대량 처리 파이프라인이면 Haiku → 실패 케이스만 Sonnet으로 재시도하는 2단 구조가 비용 효율이 가장 좋다.
Pro·Max 플랜별 모델 접근 — “Pro면 Opus만”의 오해
claude pro 어떤 모델이 중요한 질문이 아니라 주간 한도가 더 중요한 변수다. 2026-04 기준 Claude.ai 유료 플랜은 Pro $17/월(연간 결제) 또는 $20/월(월간 결제), Max 5x $100/월, Max 20x $200/월이다. Pro부터는 대화마다 드롭다운으로 Opus/Sonnet/Haiku 전환 가능하다. 플랜을 올릴 때 데이터 학습·보관 정책이 어떻게 바뀌는지는 Claude 프라이버시·데이터 정책 정리 쪽을 같이 보자.
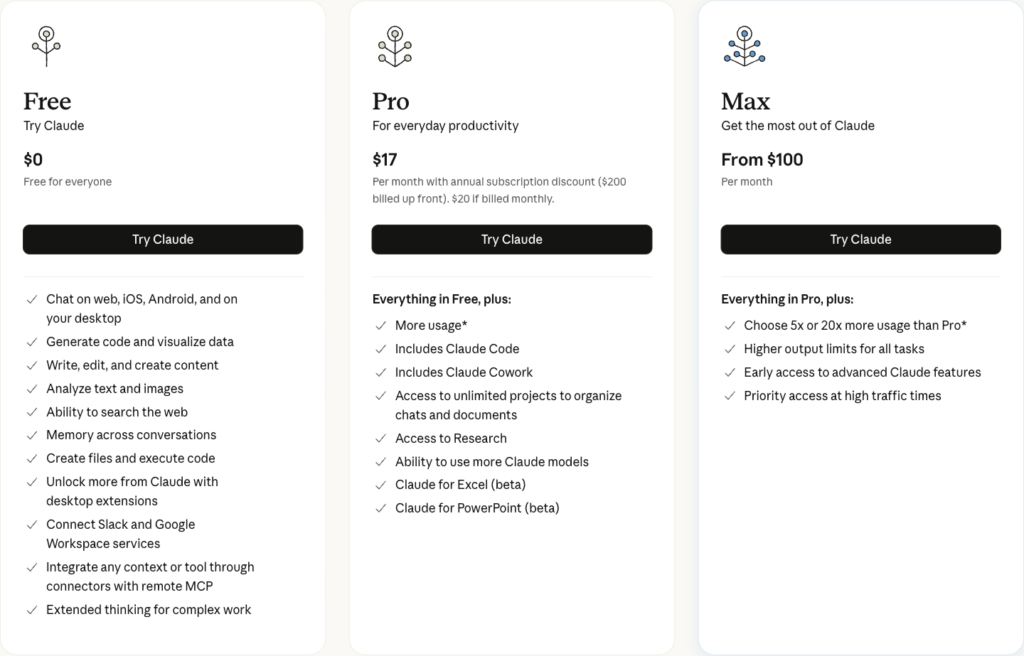
그림 3. Claude.ai 플랜별 요금 — Free / Pro / Max 3열 구성. Max 카드에서 5x(Pro 대비 5배 사용량)와 20x(20배) 옵션을 선택해 월 요금이 바뀐다.
문제는 claude pro opus 사용량 제한이다. 2025-08-28 주간 쿼터 도입 이후 Opus 전용 cap이 따로 걸린다. Anthropic은 정량 수치를 공개하지 않고 있고(“Usage limits apply” 문구만), 사용량은 시점·수요에 따라 변동한다. 커뮤니티 보고와 실사용 체감을 종합하면 Pro에서 Opus는 쓸 수는 있지만 주간 cap에 빠르게 걸리고, 상시 Opus가 필요하면 claude max 플랜 opus 구성(Max 5x 이상)이 합리적이다.
플랜 선택을 한 줄 정리하면 — 월 1-2회면 Free, 주 단위 작업이면 Pro, 일 단위 고강도 Opus면 Max 5x, 팀·에이전트 운용이면 Max 20x 또는 API다. 기본은 Sonnet, 난제만 Opus로 돌입하는 운용이 공식·실용 양면에서 합리적이다.
체감 포인트 — Opus 4.7 퇴보 논란과 한국어 품질
공식 스펙만으로 잡히지 않는 지점이 있다. claude 4.7 사용법 vs 4.6을 검색하는 사람들 상당수가 업그레이드 체감 품질에 혼란을 겪기 때문이다. 클로드 오퍼스 소넷 하이쿠 각각의 체감 차이는 공식 벤치마크만으론 완전히 설명되지 않는다.
커뮤니티에서는 Opus 4.7 출시 직후부터 일부 벤치마크 급락 보고가 나왔다. 한 비공식 측정에선 NYT Connections extended에서 Opus 4.6 94.7% → Opus 4.7 41.0%로 급락했다는 보고가 있다(비공식 커뮤니티 측정: roborhythms, HN). 창작 톤이 “더 기계적이고 불릿·헤더 위주”라는 지적도 있었다. Anthropic 공식 고지 — “더 직접적이고 덜 아첨하는 톤, 이모지 감소” — 도 이 방향을 뒷받침한다. 새 토크나이저로 동일 대화가 최대 35% 더 많은 토큰을 쓰면서 주간 cap이 더 빨리 소진된다는 불만도 따라붙었다.
한국어 품질은 솔직히 Anthropic이 개별 벤치마크를 공개한 적이 없다. MMMLU 다국어 점수(Opus 4.7 91.5%)만 있고 한국어 분리 점수는 없다. 한국 커뮤니티에선 Claude의 한국어가 자연스럽다는 체감 평이 공통적이지만 정량 근거는 없다. 필자가 같은 한국어 프롬프트 20개를 세 모델에 돌려본 n=1 결과로는 Opus 4.7과 Sonnet 4.6 차이는 거의 없었고, Haiku 4.5가 어휘 선택에서 조금 더 영어 번역투에 가까웠다. 일반화할 샘플은 아니다.
본인 워크로드의 대표 프롬프트 20개를 세 모델에 돌려 A/B를 직접 보는 게 가장 빠르다.
자주 묻는 질문 (FAQ)
여기까지 읽었다면 Claude Opus vs Sonnet vs Haiku 차이를 결정 트리 수준까지 잡았을 것이다. 남은 세부 질문은 아래에서 빠르게 짚는다.
Claude Opus와 Sonnet의 가장 큰 차이는 무엇인가요?
Opus 4.7 SWE-bench 87.6% vs Sonnet 4.6 79.6%로 복잡 추론에서 Opus가 앞서지만 가격은 5:3, 토큰 소모까지 감안하면 실질 차이는 더 크다. 일상은 Sonnet, 난제만 Opus로 간다.
Claude Pro 구독자는 어떤 모델을 써야 하나요?
기본은 Sonnet 4.6으로 충분하다. Opus도 쓸 수 있지만 2025-08 이후 Opus 전용 주간 cap이 별도로 걸려 금방 소진된다. “일상 Sonnet, 난제만 Opus”가 Pro와 가장 잘 맞는 운용이다.
Haiku는 Sonnet보다 품질이 많이 떨어지나요?
SWE-bench 기준 Haiku 4.5(73.3%)와 Sonnet 4.5(77.2%)는 3.9pp 차다. 현 세대 Sonnet 4.6과는 격차가 있지만 일상 문답·대량 처리에는 실무적으로 부족함이 없다는 평이 많다.
코딩 작업에는 Opus가 무조건 나은가요?
Opus 4.7은 SWE-bench로 +8pp 앞서지만 Sonnet 4.6도 79.6%로 최상위권이다. 개발자 59%가 Opus 4.5보다 Sonnet 4.6을 선호한 공식 수치도 있어 대형 리팩터링만 Opus면 된다.
긴 문서 요약에는 어느 모델을 써야 하나요?
Opus 4.7과 Sonnet 4.6 모두 1M 토큰 컨텍스트를 프리미엄 없이 제공한다. Haiku는 200k 제한이라 500k 이상 문서엔 부적합. 단순 요약은 Sonnet, 복잡한 분석·추론까지 필요하면 Opus로 간다.
한국어 처리는 세 모델이 차이가 있나요?
Anthropic은 한국어 개별 벤치마크를 공개하지 않았다. 다국어 MMMLU는 Opus 4.7 91.5% 수준이다. 한국 커뮤니티의 자연스러움 체감 평은 공통적이나 정량 근거는 없다. 본인 워크로드로 A/B가 가장 빠르다.
Claude.ai 웹에서 모델을 자유롭게 바꿀 수 있나요?
Pro 이상 유료면 대화마다 드롭다운으로 전환할 수 있다. Free는 Sonnet 4.6이 기본이고 공식 페이지에 Opus 접근이 명시돼 있지 않다. 상시 Opus가 필요하면 Max 5x 이상을 검토하자.
API 비용은 세 모델이 얼마나 차이 나나요?
Opus : Sonnet : Haiku = 5 : 3 : 1. 1M 토큰당 Opus $5/$25, Sonnet $3/$15, Haiku $1/$5이다. Batch API는 전 모델 50% 할인, 캐시 읽기는 입력의 10%.
관련 글
- Claude 모바일 앱 사용법 (iOS·Android) — 모바일에서 모델 전환하는 법
- Claude 프라이버시·데이터 정책 정리 — 어떤 데이터가 학습에 쓰이는지
- Claude API 비용 계산 가이드 (추후 발행) — 토큰 단위 정확 견적
- Claude vs GPT vs Gemini 2026 비교 (추후 발행) — 외부 모델까지 넓은 비교
다음 단계로는 Pro 구독자면 오늘 바로 Sonnet 4.6 기본 + Opus 4.7 에스컬레이션 패턴으로 사용 습관을 바꿔보거나, API 도입 검토 중이면 추후 발행될 비용 계산 글에서 월간 예산을 시뮬레이션해 보자.